2015年,UCloud在国内云厂商中首先推出了K80-GPU云主机。此后,我们又相继推出了P40、V100等GPU云主机,定制化物理机以及UAI-Train, UAI-Inference等以GPU为基础的AI产品,为人工智能用户持续创造价值。如今,我们更进一步,推出专门的GPU可用区。通过对架构精裁,其相比于普通可用区,GPU价格降低20%,带宽价格降低64%,并支持10 g/25 g物理网络和VPC私有网络,凭借独享性能,丰富产品互联,自助购买,按月租赁,帮助用户避免自行维护GPU集群做人工智能训练的高昂投入。
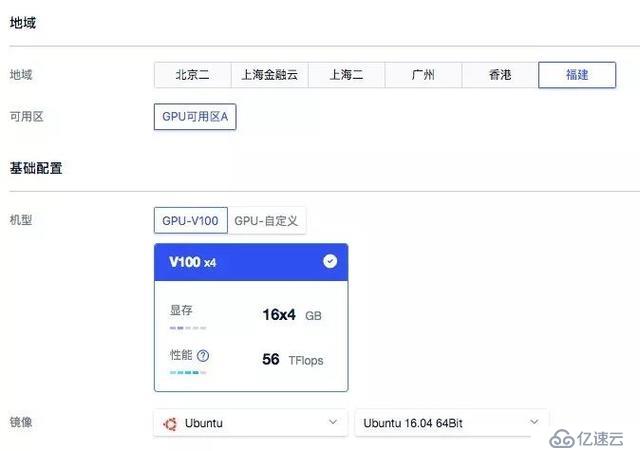
目前,福建GPU可用区一个已对全部用户开放,并支持在控制台直接购买下单。
<>强降低20%成本,支持按月付费
GPU使用成本高,一方面是GPU卡本身非常昂贵,另一方面功耗与机柜成本几乎占据了整体成本的40%,而这部分成本可以被有效降低。为此UCloud在国内臻选电力成本较低且符合基础标准的机房建立GPU可用区。此次上线的GPU可用区位于福建省,为省级骨干IDC机房,符合国际数据中心标准Tier3,提供移动线路。
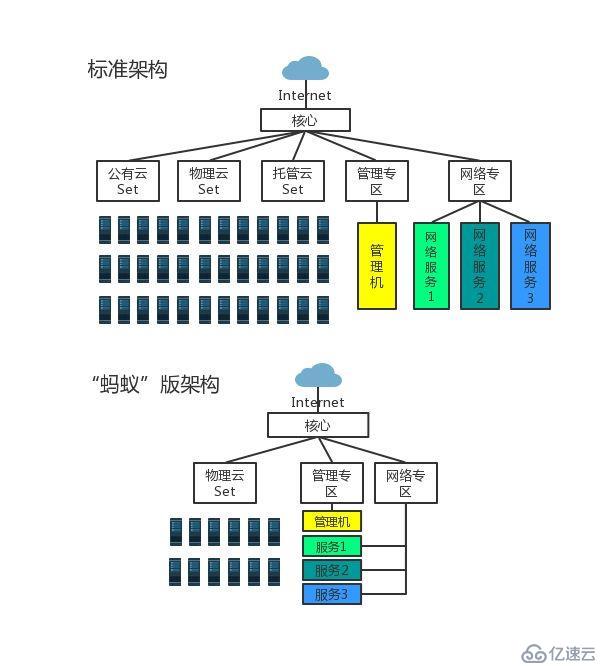
UCloud的云计算核心原本为标准可用区设计,目的是支撑上万级别的服务器,近百种不同的云计算服务。为了提升整体性价比,我们花费1周时间,便对GPU可用区快速进行了定制,推出了一个全新版本的迷你型云计算核心,内部代号“蚂蚁”。“蚂蚁”核心压缩了超过50%的云控制面成本,依然能支撑起完整的物理云主机与网络产品并提供稳定的服务。
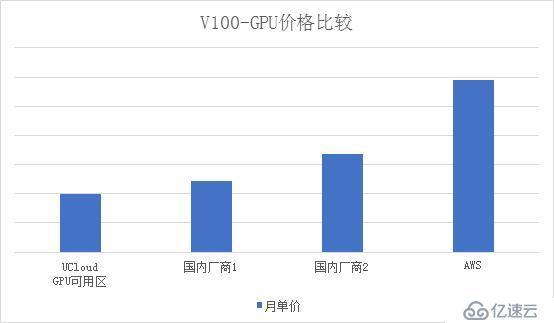
受益于功耗,机柜,云计算核心摊销成本的降低,GPU可用区的物理云单价比UCloud其他标准可用区都要便宜20%。以V100物理云为例,GPU可用区在北京二可用区E的列表单价降低5000元/月,和业内相比也有突出的价格优势.UCloud亦提供更具性价比的GPU机型可供选择。
GPU可用区的计费模式与其他可用区一致,物理机支持按月与按年付费,可随时释放。用户不必一次性投入巨大的开支,可自如增减集群规模,应对市场的动态变化。此外,福建GPU可用区提供移动单线网络,带宽费用比其他可用区降低64%。
<强>最大单精浮点性能104 TFLOPs独享物理机
GPU可用区以成熟的物理云产品体系为依托。计算,存储,网络性能均没有任何虚拟化带来的额外开销。这对AI训练这样看重绝对性能的场景非常重要。
一台GPU物理机最大能支持104 TFLOPs的单精度浮点性能,约等于2000颗CPU的算力。采用10 g与25克两套物理网络环境.25G网络带来更高的集群运算效率,集群规模≥10台计算节点时,均推荐采用25 g。和普通可用区提供的GPU云主机相比,整体性能翻倍。

物理云主机产品已实现后台资源交付入库,系统装机等流程高度自动化,并支持多种镜像,多种RAID模式可选。用户直接在控制台点选后就自动执行装机操作,30分钟内装机完成即可使用,免去传统物理机运输,搭建,部署,调试等冗长过程。

物理云主机装机中
针对物理机难以避免的硬件故障隐患,UCloud硬件运维团队维护了详细的固件问题列表,发现隐患会及时发起固件的全网升级;物理云主机在交付用户前,用户退还机器后均会自动执行完整的硬件检测。此外物理云集成了UCloud监控平台,通过监控提前发现磁盘故障,GPU卡温度过高等硬件问题,并通知NOC团队快速处理(7 * 24小时)。
GPU物理云的网关有A/B两套互备集群,网络流量可在AB集群之间平滑切换。由于此架构,在主网关出现故障时能实现快速切换到备用网关,最小化对用户的影响,亦能通过集群切换实现网络架构的平滑升级。通过这套模式,北京地区的物理云集群实现了从10 g网关到25 g网关的在线动态升级,用户除了低峰期网络瞬断外完全无感知。未来GPU可用区的网关也能通过这种能力不断更新版本。