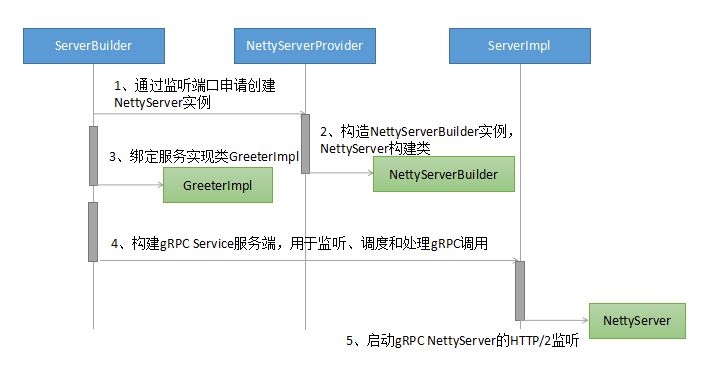
nginx代理tomcat报错:
查看nginx上游配置:
,说明:
max_fails=number ,,,,
#设定Nginx与服务器通信的尝试失败的次数。在fail_timeout参数定义的时间段内,如果失败的次数达到此值,Nginx就认为服务器不可用。在下一个fail_timeout时间段,服务器不会再被尝试。失败的尝试次数默认是1。设为0就会停止统计尝试次数,认为服务器是一直可用的。你可以通过指令proxy_next_upstream, fastcgi_next_upstream和memcached_next_upstream来配置什么是失败的尝试。默认配置时,http_404状态不被认为是失败的尝试。
fail_timeout=time ,,,,,
#设定服务器被认为不可用的时间段以及统计失败尝试次数的时间段。在这段时间中,服务器失败次数达到指定的尝试次数,服务器就被认为不可用。默认情况下,该超时时间是10秒。
,在实际应用当中,如果你后端应用是能够快速重启的应用,比如nginx的话,自带的模块是可以满足需求的。但是需要注意。如果后端有不健康节点,负载均衡器依然会先把该请求转发给该不健康节点,然后再转发给别的节点,这样就会浪费一次转发。
可是,如果当后端应用重启时,重启操作需要很久才能完成的时候就会有可能拖死整个负载均衡器。此时,由于无法准确判断节点健康状态,导致请求处理住,出现假死状态,最终整个负载均衡器上的所有节点都无法正常响应请求。由于公司的业务程序都是java开发的,因此后端主要是nginx集群和tomcat集群。由于tomcat重启应部署上面的业务不同,有些业务启动初始化时间过长,就会导致上述现象的发生,因此不是很建议使用该模式。
并且ngx_http_upstream_module模块中的服务器指令中的max_fails参数设置值,也会和ngx_http_proxy_module模块中的的proxy_next_upstream指令设置起冲突。比如如果将max_fails设置为0,则代表不对后端服务器进行健康检查,这样还会使fail_timeout参数失效(即不起作用)。此时,其实我们可以通过调节ngx_http_proxy_module模块中的proxy_connect_timeout指令,proxy_read_timeout指令,通过将他们的值调低来发现不健康节点,进而将请求往健康节点转移。
,
增加检测次数,及超时时间修复: