介绍
本篇文章为大家展示了互联网的分布式ID的示例分析,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID,在互联网企业中,大部分公司使用的都是Mysql,并且因为需要事务支持,所以通常会使用Innodb存储引擎,UUID太长以及无序,所以并不适合在Innodb中来作为主键,自增ID比较合适,但是随着公司的业务发展,数据量将越来越大,需要对数据进行分表,而分表后,每个表中的数据都会按自己的节奏进行自增,很有可能出现ID冲突。这时就需要一个单独的机制来负责生成唯一ID、生成出来的身份证也可以叫做<强>分布式ID 强,或<强>全局ID 强。下面来分析各个生成分布式ID的机制。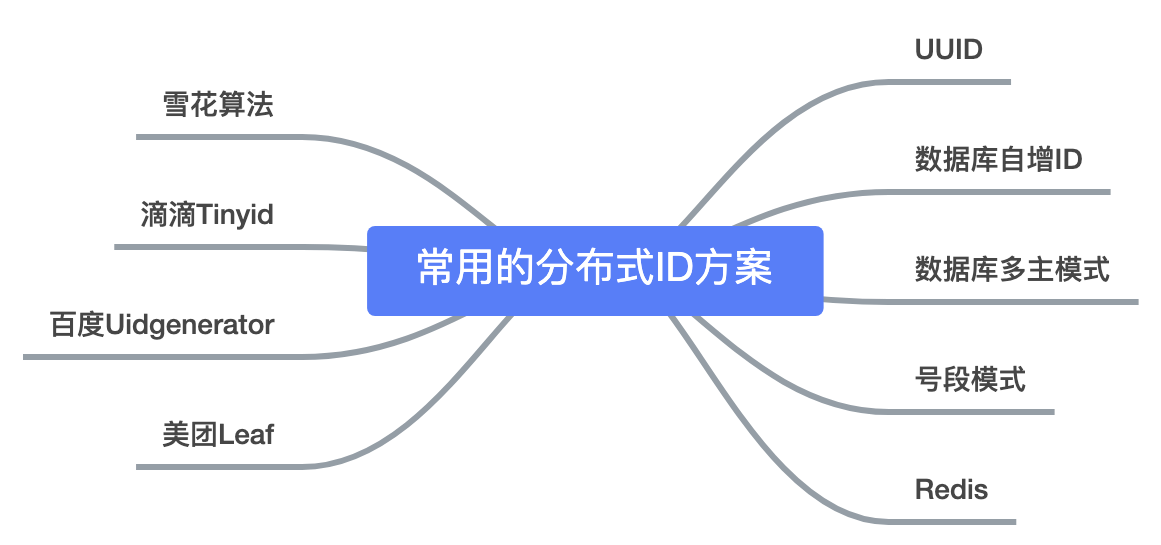 互联网的分布式ID的示例分析
互联网的分布式ID的示例分析