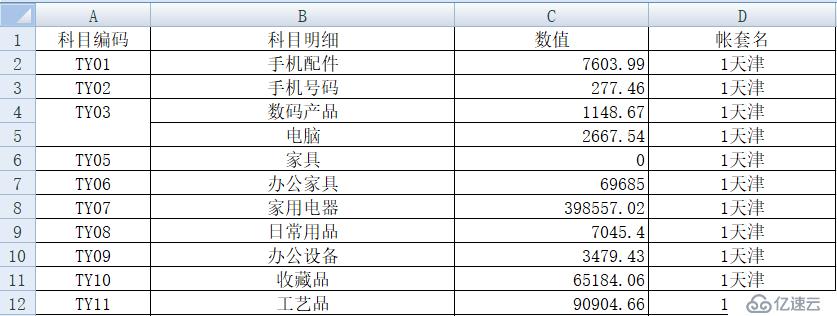
问题描述
? ?在工作中时常会遇到对Excel表格的处理。当编辑一张Excel表格时,发现表格的列数太多,而行数较少,为方便打印,这时你或许会希望将该表格行列转换,或许是为了做进一步做统计分析,当前格式不太方便,这时也会用到行列转换。
? ?下面这种交叉式的Excel表是很常见的格式,用来填写和查看都比较方便:
? ?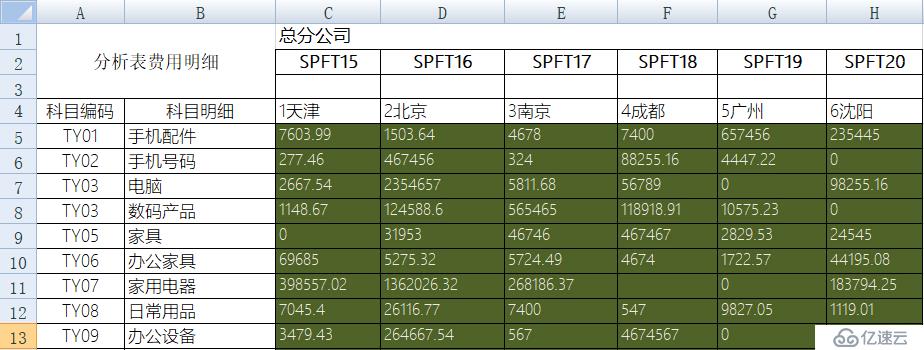
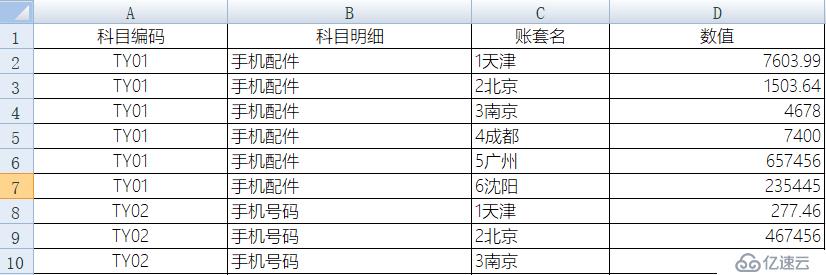
? ?但是,如果想做进一步的统计分析,这种格式就不方便了,需要行列转换,变成如下格式的明细表:
? ?
? ?显然,手工操作会非常麻烦,若数据量小还可以,数据量大了会耗费大量时间,简直就是灾难。
? ?我们就以此为例,举例说明几种常见的解决方法。
解决方法
方法1:Excel数据透视表
? ?Excel可以通过数据透视表支持行列转换功能,效果如下图:
? ?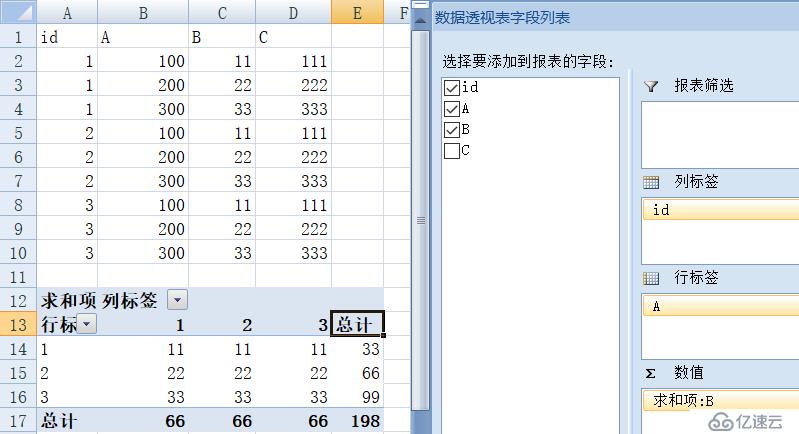
? ?显然,这并不是我们想要的格式.Excel的数据透视表可以满足简单格式的行列转换,但如果格式稍微复杂,转换效果往往是不尽人意。
方法2:编程语言
? ?以写程序来解决,思路也很简单:
? ?<强>。加载excel文件,装载需要的表工作表。
? ?<强>。读取“账套”名所在行,将其转换成字符串数组。
? ?<强>。读取“科目编码”所在列,将其转换成字符串数组。
? ?<强>。按“科目编码”分组,与“账套”名数组构造一张表。
? ?<强>。根据“账套”名对应的数据,遍历所有的明细值填充到相应的表中。
? ?<强>。这样就可以构造出对应的明细表来。
? ?如果用<强> Java 来实现,初步估计代码量也不会少于200行,若需要结果输出成excel文件则开发工作量会更多。虽然excel <强> 强自己提供了VBA,但那个麻烦程度谁用谁知道,不提也罢。那其它的语言呢?传说python <强> 有处理行列转换的功能(熊猫包里有主功能),代码量相对于Java会少很多,我们来试一下:
import pandas as pd
,,,import numpy as np
,,,df =, pd.read_excel (excel“D: \ \ \ \ pandas.xlsx",, 0,, 3)
,,,cols =, df.columns.values.tolist(), #获取数据头信息
,,,#移去前两列,只保留需要行列转换的列
,,,cols.remove(& # 39;科目编码& # 39;)
,,,cols.remove(& # 39;科目明细& # 39;)
,,,#构造一个,列表。
,,,?[]
,,,for col 拷贝关口:
,,,,,,,df1 =, df.pivot_table (index =,(& # 39;科目编码& # 39;,& # 39;科目明细& # 39;],,values =,(卡扎菲))
,,,,,,,df1.rename(列={坳:& # 39;数值& # 39;},,原地=True)
,,,,,,,df1[3]=坳
,,,,,,,#转换后的数据追加到,frames 中。
,,,,,,,frames.append (df1)
,,,#,concat 将相同字段的表首尾相接
,,,结果=pd.concat(帧)
,,,result.rename(列={3:,& # 39;帐套名& # 39;},,原地=True)
,,,result.to_excel (excel & # 39; D: \ \ \ \ pandas_n.xlsx& # 39;,, sheet_name=& # 39;科目明细& # 39;),,,,import pandas as pd ,,, import numpy as np
,,,df =, pd.read_excel (excel“D: \ \ \ \ pandas.xlsx",, 0,, 3)
,,,cols =, df.columns.values.tolist(), #获取数据头信息
,,,#移去前两列,只保留需要行列转换的列
,,,cols.remove(& # 39;科目编码& # 39;)
,,,cols.remove(& # 39;科目明细& # 39;),,,,#构造一个,列表。
,,,?[],,,,for col 拷贝关口:
,,,,,,,df1 =, df.pivot_table (index =,(& # 39;科目编码& # 39;,& # 39;科目明细& # 39;],,values =,(卡扎菲))
,,,,,,,df1.rename(列={坳:& # 39;数值& # 39;},,原地=True)
,,,,,,,df1 [3]=col ,,,,,,, #转换后的数据追加到,frames 中。
,,,,,,,frames.append (df1),,,, #, concat 将相同字段的表首尾相接
,,,结果=pd.concat(帧)
,,,result.rename(列={3:,& # 39;帐套名& # 39;},,原地=True)
,,,result.to_excel (excel & # 39; D: \ \ \ \ pandas_n.xlsx& # 39;,, sheet_name=& # 39;科目明细& # 39;)
? ?效果还不错,果然比较简洁!这是Python生成的excel文件:
? ?