
Hadoop的三种模式的安装
<编辑>一。 Hadoop的三种模式1。单节点模式
2。伪分布模式,一般用于测试
3。完全分布模式,集群环境,常用
Hadoop主从节点分解:
<编辑>二。安装环境1。单机模式,一台主机,172.25.22.10
2。伪分布模式,一台主机,172.25.22.11
3。完全分布模式,三台主机,172.25.22.10 11 12
软件包:
hadoop-1.2.1.tar。广州
jdk-7u79-linux-x64.tar。广州
<编辑>三。配置步骤之单机模式<我>注意:在配置环境时,最好以一个普通用户的身份去配置,三种模式都是以普通用户hadoop身份运行的 <我>
1。
单机模式只有一个节点,只需将hadoop包解压到相应的位置下即可,本次解压的目录是在/home/hadoop下,然后做一个软链接,方便之后切换目录。和修改配配置文件中文件目录的位置
ln - s hadoop-1.2.1/hadoop
ln - s jdk1.7.0_79/java
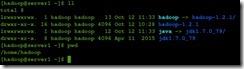
2。修改一下配置文件
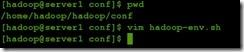
将java的目录写进去

3。下一步配置ssh无密码登陆到本机ssh - keygen
ssh-copy-id 172.25.22.10
配置完成,可以直接ssh localhost到本机
4。配置完成后,测试
首先建立一个输入目录
Cp mkdir输入conf/*。xml输入/
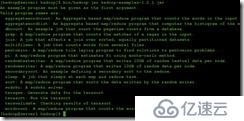
拿一个例子测试一下,
bin/Hadoop jar hadoop-examples-1.2.1。jar grep输入输出的dfs [a - z。)+ '
输出输出的目录可自动生成
看到hadoop里边有这个目录,而且可以查看
如果拿网页看的话
<你> http://172.25.22.10:50070 dfshealth。jsp 可以看到hdfs中保存的文件
<你> http://172.25.22.10:50030 jobtracker。jsp 可以看到正在处理的过程
<编辑>四。伪分布模式的配置由于伪分布模式也是在一个节点上,在单节点的模式下,配置其几个配置文件
1。编辑其配置下的配置文件
# # # # # vim核心位点。xml添加内容
& lt; property>
,,,& lt; name> fs.default.name
,,,& lt; value> hdfs://172.25.22.10:9000
,,,& lt;/property>
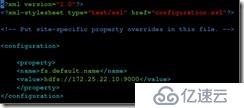
# # # # # vim mapred-site。xml
& lt; property>
,,,& lt; name> mapred.job.tracker
,,,& lt; value> 172.25.22.10:9001
,,,& lt;/property>

# # # # # # vim hdfs-site。xml
& lt; property>
,,,& lt; name> dfs.replication
,,,& lt; value> 1 & lt;/value>
,,,& lt;/property>
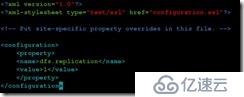
配置文件修改完成
2。对hadoop进行格式化
bin/hadoop namenode格式
3。开启所有进程
bin/开始。sh

4。查看进程
/home/hadoop/java/bin/jps
所有的进程都在这一个节点上,
JobTracker # # # # #负责任务调度
TaskTracker # # # # #负责数据处理SecondaryNameNode
NameNode # # # # #包含元数据信息
DataNode ,# # # # #数据节点,存储数据
5。测试
bin/hadoop——输入
conf/bin/hadoop jar hadoop-examples-1.2.1。jar grep输入输出的dfs [a - z。)+ '
这里的输入和之前那个输入是完全不一样的,这个是存储在分布式文件系统中的
用网页查看可以看到
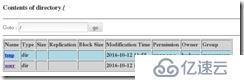
三台主机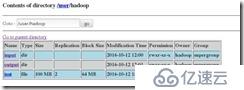
三台主机:




