火花快的原因
1。内存计算
2。DAG
引发壳已经初始化好了SparkContext,直接用sc调用即可

血统血统
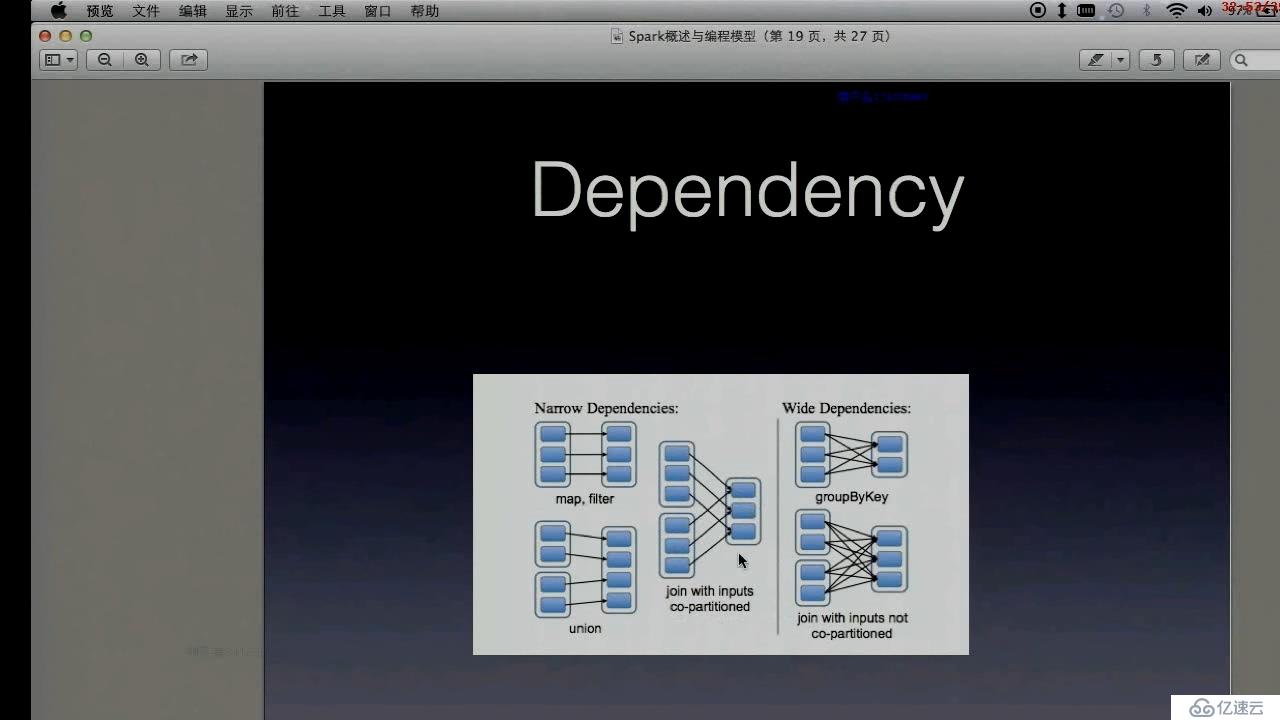
广义和狭义依赖抽样
每个抽样分区最多被一个子抽样partirion依赖
/sbin(系统二进制)放的都是涉及系统管理的命令。
有些系统里面,普通用户没有执行这些命令的权限。
有些系统里面,普通用户的路径不包括/sbin
data.cache 数据放到内存中
提交任务

scala代码
package cn.chinahadoop.spark
import org.apache.spark。{SparkContext,, SparkConf}
import scala.collection.mutable.ListBuffer
import org.apache.spark.SparkContext._/* *
,* Created by chenchao 提醒14-3-1。
,*/class Analysis {
}
{object 分析
def 才能;主要(args :数组(String)) {
,,,如果(args.length !=, 2) {
,,,,,println (“Usage : java -jar code.jar , file_location save_location”)
,,,,,system . exit (0)
,,,}
,,
,,,val conf =, new SparkConf ()
,,,conf.setSparkHome(“/数据/软件/crazyjvm/火花”)
,,,,
,,,val sc =, new SparkContext(配置)
,,,val data =, sc.textFile (args (0))
,,data.cache
,,,println (data.count)
,,,data.filter (_.split (', ') .length ==, 3) . map (_.split (', ') (1)) . map ((_, - 1)) .reduceByKey (_ + _)
,,,. map (x =祝辞,(x._2, x._1)) .sortByKey (false) . map (=, x 祝辞,(x._2, x._1)) .saveAsTextFile (args (1))
,,}
}





