
互联网发展到现在,由于数据量大,操作并发高等问题,大部分网站项目都采用分布式的架构。而分布式系统最大的特点数据分散,在不同网络节点在某些时刻(数据未同步完,数据丢失),数据会不一致。
在2000年,Eric Brewer教授在PODC的研讨会上提出了一个猜想:一致性,可用性和分区容错性三者无法在分布式系统中被同时满足,并且最多只能满足其中两个!
在2002年,林奇证明其猜想,上升为定理。被这就是大家所认知的帽定理。
帽是所有分布式数据库的设计标准,例如动物园管理员,复述,HBase等的设计都是基于帽理论的。
帽定义
所谓的帽子就是分布式系统的三个特性:
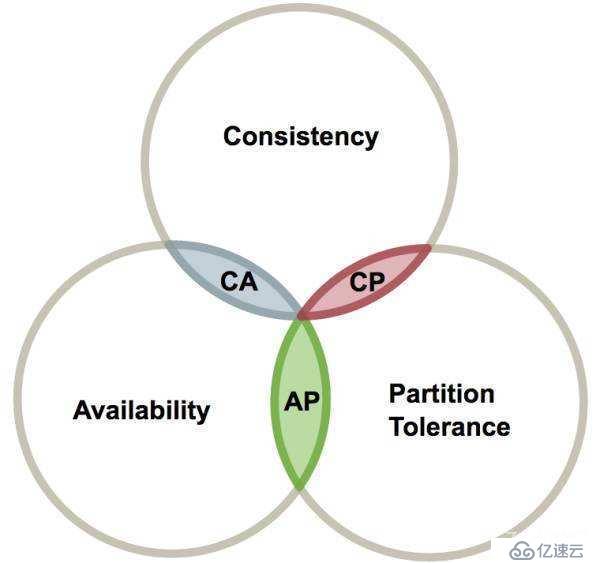
-
<李>一致性,一致性。所有分布式节点的数据是否一致。
<李>可用性、可用性。在部分节点有问题的情况(数据不一致,节点故障)下,是否能继续响应服务(可用)。
<李>分区宽容,分区容错性。允许在节点(分区)数据不一致的情况。
深入理解
有A, B, C三个分布式数据库。
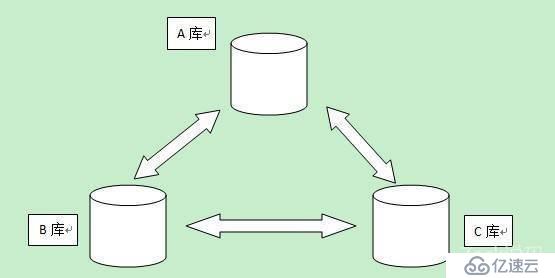
当A, B, C的数据是完全相同,那么就符合定理中的一致性(一致性)。
假如一个的数据与B的数据不相同,但是整体的服务(包含A, B, C的整体)没有宕机,依然可以对外系统服务,那么就符合定理中的可用性(可用性)。
分布式数据库是没有办法百分百时刻保持各个节点数据一致的。假设一个用户再一个库上更新了一条记录,在更新完这一刻,A与B, C库的数据是不一致的。这种情况在分布式数据库上是必然存在的。这就是分区容忍(分区容错性)
当数据不一致的时候,必定是满足分区容错性,如果不满足,那么这个就不是一个可靠的分布式系统。
然而在数据不一致的情况下,系统要么选择优先保持数据一致性,这样的话。系统首先要做的是数据的同步操作,此时需要暂停系统的响应。这就是满足CP。
若系统优先选择可用性,那么在数据不一致的情况下,会在第一时间放弃一致性,让整体系统依然能运转工作。这就是美联社。
所以,分布式系统在通常情况下,要不就满足CP,要不就满足美联社。
那么有没有满足CA的呢?有,当分布式节点为1的时候,不存在p,自然就会满足了。
例子
上面说到,分区容错性是分布式系统中必定要满足的,需要权衡的是系统的一致性与可用性。那么常见的分布式系统是基于怎样的权衡设计的。
-
<李>管理员
保证CP。当主节点故障的时候,饲养员会重新选主。此时管理员是不可用的,需要等待选主结束才能重新提供注册服务。显然,饲养员在节点故障的时候,并没有满足可用性的特性。在网络情况复杂的生产环境下,这样的的情况出现的概率也是有的。一旦出现,如果依赖饲养员的部分会卡顿,在大型系统上,很容易引起系统的雪崩。这也是大型项目不选管理员当注册中心的原因。 <李>尤里卡
保证。在尤里卡中,各个节点是平等的,它们相互注册。挂掉几个节点依然可以提供注册服务的(可以配置成挂掉的比例),如果连接的尤里卡发现不可用,会自动切换到其他可用的几点上。另外,当一个服务尝试连接尤里卡发现不可用的时候,切换到另外一个尤里卡服务上,有可能由于故障节点未来得及同步最新配置,所以这个服务读取的数据可能不是最新的。所以当不要求强一致性的情况下,尤里卡作为注册中心更为可靠。 <李> Git
其实Git也是也是分布式数据库。它保证的是CP。很容易猜想到,云端的Git仓库于本地仓库必定是要保证数据的一致性的,如果不一致会先让数据一致再工作。当你修改完本地代码,想把代码到Git仓库上时,假如云端的负责人与本地的头不一致的时候,会先同步云端的头到本地脑袋,再把本地的头同步到云端。最终保证数据的一致性。
更多技术文章,精彩干货,请关注
个人博客:zackku.com
微信公众号:扎克说码





