
社区提供的读写分离架构图如下: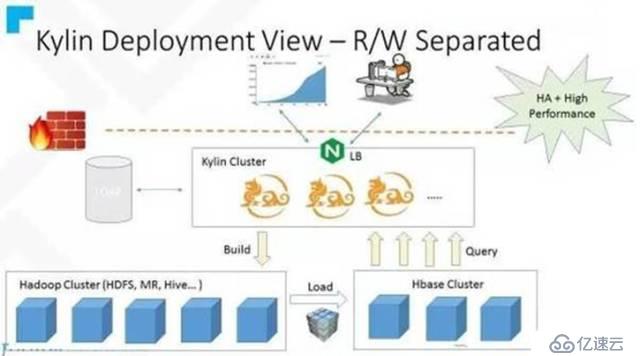
下面解释一下哪些用cluster1的参数,哪些文件用cluster2的参数。如果用cluster1的参数,直接从cluster1拷贝过来就行了。
这些文件都在麒麟美元/HOME/hadoop_conf这个目录下
核心位点。xml——cluster1这个里面配置了hdfs的地址
hbase-site。xml——cluster2
hdfs-site。xml——cluster2这个里面配置了nameservice的参数,没有它无法解析nameservice
蜂巢——xml cluster1
mapred-site.xml——cluster1
我们用麒麟用户去启动及服务,所以配置一下麒麟用户环境变量,修改~/ashrc这(个文件
添加上这些
export HBASE_CONF_DIR=$麒麟/HOME_hadoop_conf
export HIVE_CONF=$麒麟/HOME_hadoop_conf
export HADOOP_CONF_DIR=$ KYLIN_HOME/hadoop_conf
! ! ! ! ! ! ! ! ! ! ! ! ! !
出口HBASE_CONF_DIR=$ KYLIN_HOMEhadoop_conf
这个HBASE_CONF_DIR很重要,因为麒麟是用过HBASE去读取hdfs——网站和core-site.xml这两个文件从而读取hdfs的环境变量的,不加的话默认会读鼎晖目录下HBASE的配置,我因为这个东西卡了好几天,加了好几天班才发现好。想哭....而麒麟官方根本没有写,坑爹啊. .
! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! !
配置conf/kylin.properties和tomcat/conf/server.xml
/conf/kylin.properties根据自己需要去配置,主要配置下蜂巢和hbase的相关参数,
/conf/tomcat server.xml主要有2个地方需要注意:
1。keystore
& lt;连接器端口=?443”;协议=皁rg.apache.coyote.http11.Http11Protocol"
maxThreads=?50”;SSLEnabled=皌rue"计划=癶ttps"安全=皌rue"
keystoreFile=癱onf/.keystore"keystorePass=癱hangeit"
clientAuth=癴alse"sslProtocol=癟LS"/在
需要去生成相应的密钥存储库文件,或者直接把这段注释掉
2。我在测试环境上没有修改这个可以正常运行,在生产机部署的时候,打开前端的ui,出现无法加载模型,配置,和环境变量的问题,同时会在前台弹出“未能采取行动”的提示
经过好几天的查找,发现是前端获取资源在解压缩的时候出现问题,把压缩关掉
在
& lt;连接器端口=?070”;协议=癏TTP/1.1“
connectionTimeout=?0000“
redirectPort=?443“
压缩=爸?
compressionMinSize=?048“
noCompressionUserAgents=癵ozilla, traviata"
compressableMimeType=皌ext/html、文本/xml、text/javascript应用程序/javascript应用程序/json文本/css文本/plain"
/祝辞中
把压缩=爸?改为压缩=皁ff"
修改KYLIN_HOME/conf/kylin.perproties,
kylin.source.hive.client=直线
# # jdbc url的改为cluster1的蜂巢地址
kylin.source.hive。beeline-params=n根——hiveconf hive.security.authorization.sqlstd.confwhitelist.append=' mapreduce.job。 | dfs。 ' - u jdbc: hive2://stream3:25002
# #改为cluster2的hdfs地址
kylin.storage.hbase.cluster-fs=hdfs://stream-master1:8020
另外我在构建任务过程中第16步失败,原因是分配资源不够,在KYLIN_HOIME/conf/kylin_job_conf.xml中添加一下mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的这两个参数,把值配大一点就好了。
然后启动就可以了。




