
1。关于RPC
(1) RPC的概念
RPC(远程过程调用)——远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些传输协议的存在,如;TCP或UDP者,为通信程序之间携带信息数据,在OSI网络通信模型中,RPC跨越了<强>传输层和<强>应用层 .RPC使得开发包括网络分布式程序在内的应用程序更加容易。
(2) OSI网络七层模型
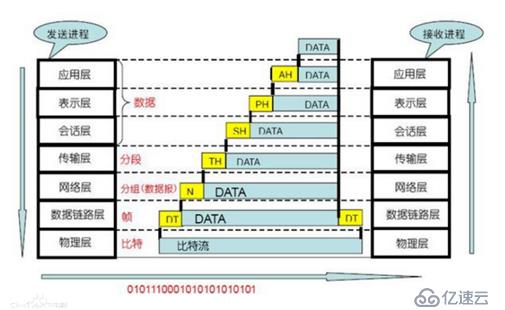
第一层:物理层。这一层主要就是传输这些二进制数据。
第二层:链路层。将上面的网络层的数据包封装成数据帧,便于物理层传输;
第三层:网络层。定义网络设备间如何传输数据;
第四层:传输层。管理着网络中的端到端的数据传输;
第五层:会话层。管理用户的会话,控制用户间逻辑连接的建立和中断;
第六层:表示层。定义不同的系统中数据的传输格式,编码和解码规范等;
第七层:应用层。定义了用于在网络中进行通信和传输数据的接口;
(3) RPC工作机制
RPC采用客户机/服务器模式:请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
通俗的说:RPC是指远程过程调用,也就是说两台服务器A, B,一个应用部署在一服务器,想要调用B服务器提供的函数和方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。也可以理解成不同进程之间的服务调用。

<>强实现的具体步骤:
第一(通讯问题):主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
第二(寻址问题):一个服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称以及名称是什么,这样才能完成调用。
第三(方法参数的网络传递):当一个服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(序列化)或编组(元帅),通过寻址和传输将序列化的二进制发送给B服务器。
第四(反序列化):B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
第五(返回值):返回值还要发送回服务器一个上的应用,也要经过序列化的方式发送,服务器一个接到后,再反序列化,恢复为内存中的表达方式,交给一个服务器上的应用
(4) RPC的作用
<强> - 让调用方感觉就像调用本地函数一样调用远端函数,让服务提供方感觉就像实现一个本地函数一样来实现服务,并且屏蔽编程语言的差异性。
<强> - 让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性
<强> - 在客户端一个上来说,会生成一个服务器B的代理。(总结)
JAVA中(5)流行的RPC框架
<强> RMI (远程方法调用):JAVA自带的远程方法调用工具,不过有一定的局限性,毕竟是JAVA语言最开始时的设计,后来很多框架的原理都基于RMI。
<强>黑森(基于HTTP的远程方法调用):基于HTTP协议传输,在性能方面还不够完美,负载均衡和失效转移依赖于应用的负载均衡器,黑森的使用则与RMI类似,区别在于淡化了注册表的角色,通过显示的地址调用,利用HessianProxyFactory根据配置的地址创建一个代理对象,另外还要引入黑森的Jar包。




