
<强>
<强>
虚拟化软件:Vmware工作站,z
10.7 Linux系统:,Centos 6.5 x86_64
采用4台安装Linux环境的机器来构建一个小规模的分布式集群。
, 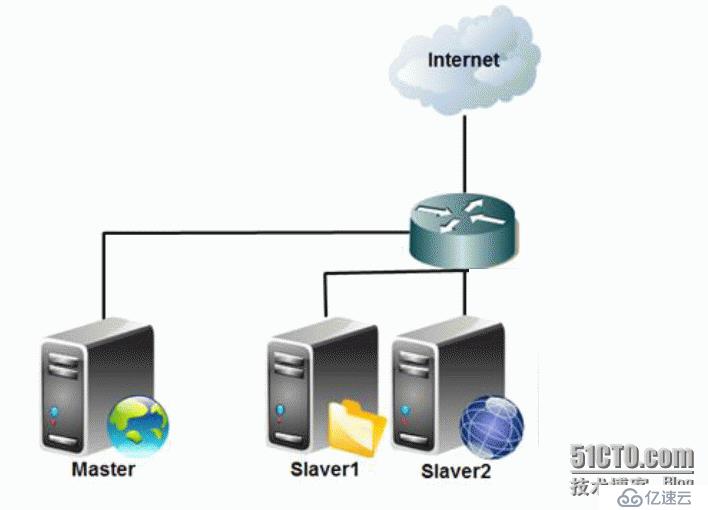
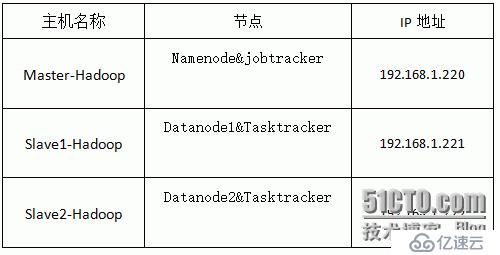
<强>集群机器详细信息
(1)配置vi,/etc/主机名

,
(2)配置vi/etc/sysconfig/network

,
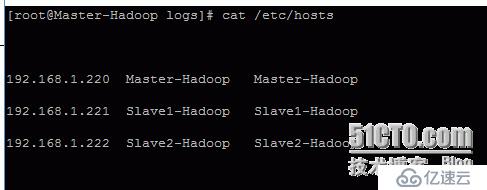
(3)配置vi/etc/hosts
,
<强>
<强> 1)重启后生效,
开启:chkconfig iptables alt=" Hadoop学习之第一章节:Hadoop配置安装">
<强>
<强>
Java的安装,,
Rpm, qa | grep, Java,,查看系统已安装的java
卸载已安装的java
, rpm - e -nodeps,(包名称)
配置环境变量vi/etc/profile
#设置java环境
出口,JAVA_HOME=/usr/java/jdk1.8.0_77
出口,JRE_HOME=/usr/java/jdk1.8.0_77/jre
出口,CLASSPATH=?$ JAVA_HOME/lib: $ JRE_HOME/lib:美元类路径
出口,路径=$ JAVA_HOME/bin: $ JRE_HOME/bin:美元路径
配置完成后效果为:
, 
<强>
<强>
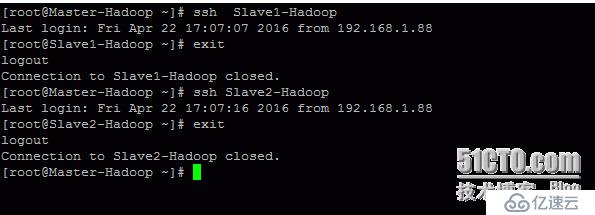
SSH设置需要在集群上做不同的操作,如启动,停止,分布式守护壳操作。认证不同的Hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
下面的命令用于生成使用SSH键值对。复制公钥形成id_rsa。酒吧到authorized_keys文件中,并提供拥有者具有authorized_keys文件的读写权限。
在其他节点上同样命令后,把所有节点的id_rsa。酒吧内容添加到authorized_keys,然后将authorized_keys分发到所有节点的/sh/目录下
配置完成后效果为:
,
<强>
<强>
<强>
<强>本文档的Hadoop版本为:hadoop-2.6.4.tar。广州
<强>
<强>
下载Hadoop以后,可以操作Hadoop集群以以下三个支持模式之一:
本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。
模拟分布式模式:这是在单台机器的分布式模拟.Hadoop守护每个进程,如hdfs,纱,MapReduce等,都将作为一个独立的Java程序运行。这种模式对开发非常有用。
完全分布式模式:这种模式是完全分布式的最小两台或多台计算机的集群。我们使用这种模式在未来的章节中。
<强>(1)文件核心位点。xml改为下面的配置:
& lt; property>
,,,, & lt; name> fs.default.name
,,,, & lt; value> hdfs://192.168.1.220:9000
& lt;/property>
& lt; property>
,,,, & lt; name> hadoop.proxyuser.root.hosts
,,,, & lt; value> 192.168.1.220
& lt;/property>
& lt; property>
,,,, & lt; name> hadoop.proxyuser.root.groups
,,,, & lt; value> * & lt;/value>
& lt;/property>
<强>(2)文件hdfs-site。xml改为下面的配置:




