
在数据库应用开发中,我们经常需要面对复杂的SQL式计算,固定分组就是其中一种。固定分组的分组依据不在待分组的数据中,而是来自于外部,比如另一张表,外部参数,条件列表等。对于特定类型的固定分组,用SQL实现还算简单(比如:分组依据来自另一张表,且对分组次序没有要求),但对于比较通用,灵活的要求,实现起来就困难了。
而对于SPL来说,完全可以轻松解决固定分组中的各类难题,下面就用几个例子来说明。
表销售存储着订单记录,其中客户列是客户名,金额列是订单金额。表销售的部分数据如下:
<强> OrderID <强>客户 <强> SellerId OrderDate <强> <强> 强量10248 vinet52013/7/4244010249tomsp62013/7/51863.410250hanar42013/7/8181310251victe32013/7/8670.810252suprd42013/7/9373010253hanar32013/7/101444.810254chops52013/7/11625.210255ricsu92013/7/122490.510256welli32013/7/15517.8要求将销售按照“潜力客户列表”进行分组,并对各组的数量列汇总求和。这里的“潜力客户”就是一种固定分组,可能来自于外部不同的条件设定:
<强>
<强>案例一:强潜力客户列表来自于另外一张表潜在的性病字段,只有四条记录,依次为:ANATR,冰山,LACOR, ZTOZ,并且客户ZTOZ不在销售表中。在输出结果时,要求按照上述记录顺序来分组汇总。
如果我们对分组的顺序没有要求,那么的SQL可以较简单地实现本案例:
选择潜力。性病作为客户端,总和(sales.amount)数量从潜在的左边加入端alt=" SPL简化SQL案例详解:固定分组">
A3:=sales.align@a(潜在:性病,客户机)
这句代码使用了函数一致,它将销售的客户字段按潜在的std照字段顺序对位分为四个组,如下:
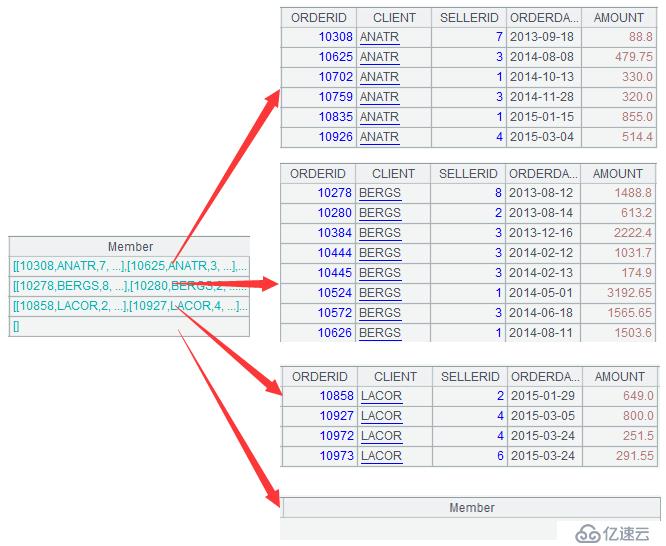
可以看的到,前三个组是销售中已有的数据,而第四个组不在销售中,因此是空值。另外,函数一致的参数选项@a表示取出分组中的所有数据,如果不用这个函数选项,则只取每组的第一条。
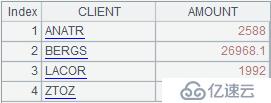
A4:=A3.new(潜在的(#). std:客户端,~ .sum(数量):金额)
这句代码用函数新产生新的序表,成员一个是potential.STD,即潜在的性病字段;另一个是~ .sum(量),即对A3中每组数据的金额字段的求和结果。最终结果如下:
<强>
<强>案例二:潜力客户列表是固定值,但客户的数量较多。
如果客户的数量较少,用SQL时可以用联盟语句将所有的客户拼成一个假表,如果客户数量较多,这么做就可不取了,必须新建一张表持久保存数据才行。而用SPL实现却可以省去建表的麻烦,代码如下:
A1=销售=db。查询(“select * from销售”)2=潜在=[“ALFKI”、“BSBEV”,“FAMIA”,“加”、“HUNGC”,“KOENE”、“LACOR”、“nort”、“快速”、“SANTG”,“THEBI”、“VINET”、“WOLZA”) 3=sales.align@a(潜在客户)4=A3.new(潜在的(#):客户端,~ .sum(数量):金额)
上述代码中,A2是个字符串组成的序列,并命名为potential.A3, A4可以像案例一那样对潜在的访问,直接引用其成员。
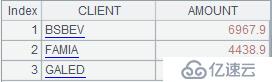
<强>案例三:潜力客户列表是外部参数,形如:“BSBEV”、“FAMIA”,“盖尔”。
外部参数经常变化,在SQL中用联盟来制造假表就更不方便的了,只能创建一个临时表,将参数解析后一条条插入临时表,再进行后续的计算。而用SPL实现则不必建立临时表,具体实现过程如下:
首先定义一个参数的客户,如下:
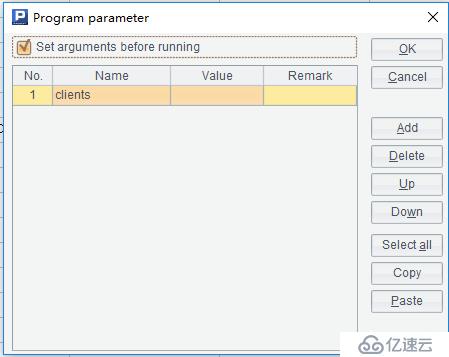
然后修改脚本文件,如下:
A1=销售=db。查询(“select * from销售”)2=潜在=clients.array () 3=sales.align@a(潜在客户)4=A3.new(潜在的(#):客户端,~ .sum(数量):金额)
运行脚本,并输入的参数值,假设参数值为“BSBEV”、“FAMIA”、“加”,如下:
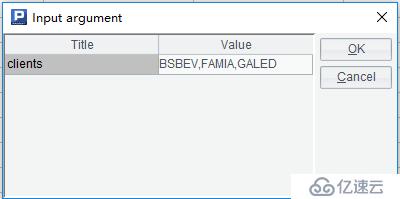
分组依据输入不同,最终计算结果也不一样。上面输入对应的结果如下:
<强>案例四:固定分组的分组依据可以是数值,也可以是条件,比如:将订单金额按照1000年,2000年,4000年划分为四个区间,每个区间一组订单,统计各组订单的总额。




