
<强>
在MapReduce框架中,洗牌是连接Map和Reduce之间的桥梁,降低要读取到地图的输出必须要经过洗牌这个环节;而减少和地图过程通常不在一台节点,这意味着洗牌阶段通常需要跨网络以及一些磁盘的读写操作,因此混乱的性能高低直接影响了整个程序的性能和吞吐量。
与MapReduce计算框架一样,作业也有洗牌阶段,通常以洗牌来划分阶段;而阶段之间的数据交互是需要洗牌来完成的。整个过程图如下所示:
,
<中心>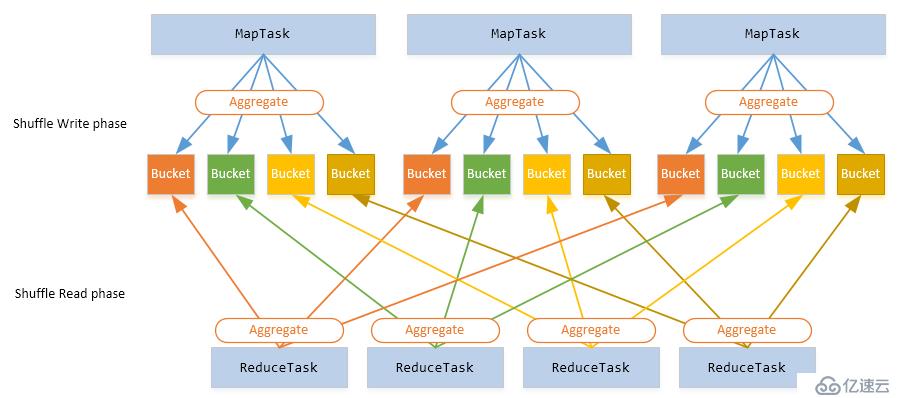
,
<强>从上面简单的介绍可以得到以下几个结论:
不管是MapReduce还是火花作业,洗牌操作是很消耗资源的,这里的资源包括:CPU、RAM、磁盘还有网络;
<强>我们需要尽可能地避免洗操作
而目前最新的火花(2.2.0)内置只支持一种洗牌实现:org.apache.spark.shuffle.sort。SortShuffleManager,通过参数spark.shuffle。经理来配置。这是标准的火花洗牌实现,其内部实现依赖了网状的框架。本文并不打算详细介绍火花内部洗牌是如何实现的,这里我要介绍社区对洗牌的改进。
<强>
在进行下面的介绍之前,我们先来了解一些基础知识。
传统的TCP套接字数据传输需要经过很多步骤:数据先从源端应用程序拷贝到当前主机的套接字缓存区,然后再拷贝到TransportProtocol司机,然后到网卡驱动程序,最后网卡通过网络将数据发送到目标主机的网卡,目标主机又经过上面步骤将数据传输到应用程序,整个过程如下:
,
<中心>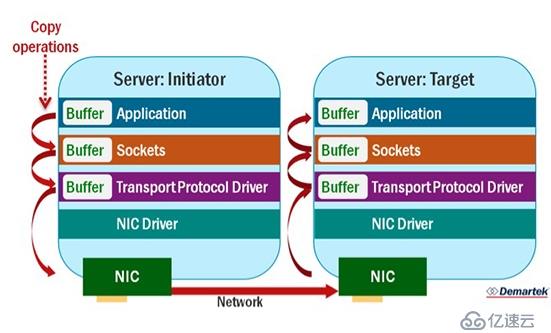
,
从上图可以看的出,网络数据的传输很大一部分时间用于数据的拷贝!如果需要传输的数据很大,那么这个阶段用的时间很可能占整个作业运行时间的很大一部分!那么有没有一种方法直接省掉不同层的数据拷贝,使得目标主机直接从源端主机内存获取数据吗?还真有,这就是RDMA技术!
RDMA(远程直接内存访问)技术全称远程直接内存访问,是一种直接内存访问技术,它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。这允许高通量,低延迟的网络通信,尤其适合在大规模并行计算机集群中使用(本段摘抄自维基百科——远程直接内存访问).RDMA有以下几个特点:
?零拷贝
?,直接硬件接口(直接硬件接口),绕过内核和TCP/IP的IO
?,亚微秒延迟
?,流量控制和可靠性是卸载在硬件
所以利用RDMA技术进行数据传输看起来像下面一样:
,
<中心>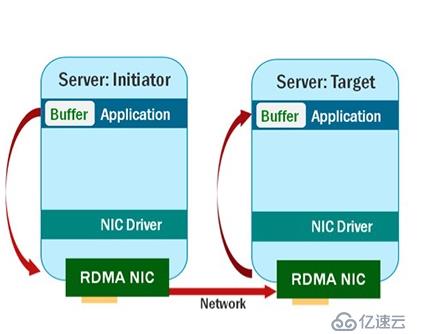
,
从上面看的出,使用了RDMA技术之后,虽然源端主机和目标主机是跨网络的,但是他们之间的数据交互是直接从对方内存获取的,这明显会加快整个计算过程。
<强>
好,现在基础的知识咱们已经获取到的了,我们正式进入本文主题。由Mellanox技术公司开发并开源的SparkRDMA ShuffleManager (GitHub地址:https://github.com/Mellanox/SparkRDMA)就是采用RDMA技术,使得火花作业在洗牌数据的时候使用RDMA方式,而非标准的TCP方式。在SparkRDMA的官方Wiki里面有如下介绍:
SparkRDMA是一种高性能、可伸缩的和高效的Apache火花ShuffleManager插件。它利用RDMA(远程直接内存访问)技术来减少随机数据传输所需的CPU周期。它减少了内存使用量为转移,而不是通过重用内存复制数据多次传统tcp协议栈。
可以看的出,SparkRDMA就是扩展了火花的ShuffleManager接口,并且采用了RDMA技术。在测试的结果显示,采用RDMA进行调整数据比标准的方式快2.18倍!
,
<中心>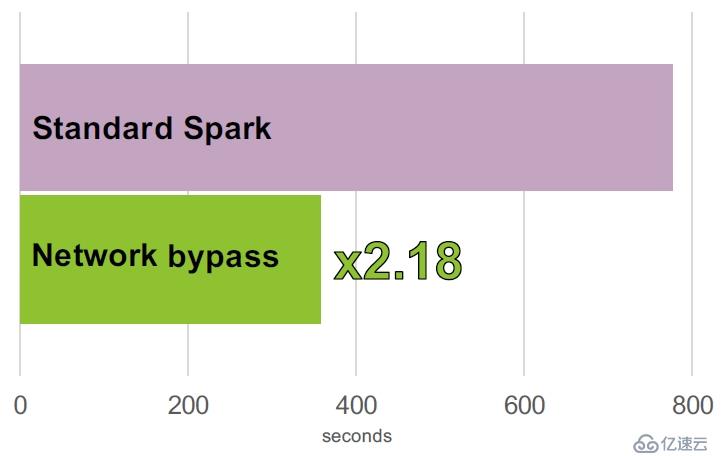
,
SparkRDMA开发者们给火花社区提交了一个问题:[火花- 22229]SPIP: RDMA洗牌加速引擎,详细的设计文档:这里。不过从社区的回复来看,最少目前不会整合到火花代码中去。
<强>
如果你想使用SparkRDMA,我们需要Apache火花2.0.0/2.1.0/2.2.0,Java 8以及支持RDMA技术的网络(比如:RoCE和Infiniband)。
SparkRDMA官方为不同版本的火花预先编译好相应的jar包,我们可以访问这里下载。解压之后会得到以下四个文件:




