<强>字符集是什么?
从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库读写分离,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。也可以指定多个写库多个读库。
字符集发展到目前的版,本已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL, SQL Server, Oracle、DB2, PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在字符集里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
<强>字符集可以干什么?
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换
分表分库,对于超过1000多万的表进行分片,最大支持1000个亿的单表分片
多租户应用,每个应用一个库,但应用程序只连接字符集,从而不改造程序本身,实现多租户化
报表系统,借助于字符集的分表能力,处理大规模报表的统计
替代Hbase,分析大数据
作为海量数据实时查询的一种简单有效方案,比如100年亿条频繁查询的记录需要在3秒内查询出来结果
<强>字符集分布式架构设计:
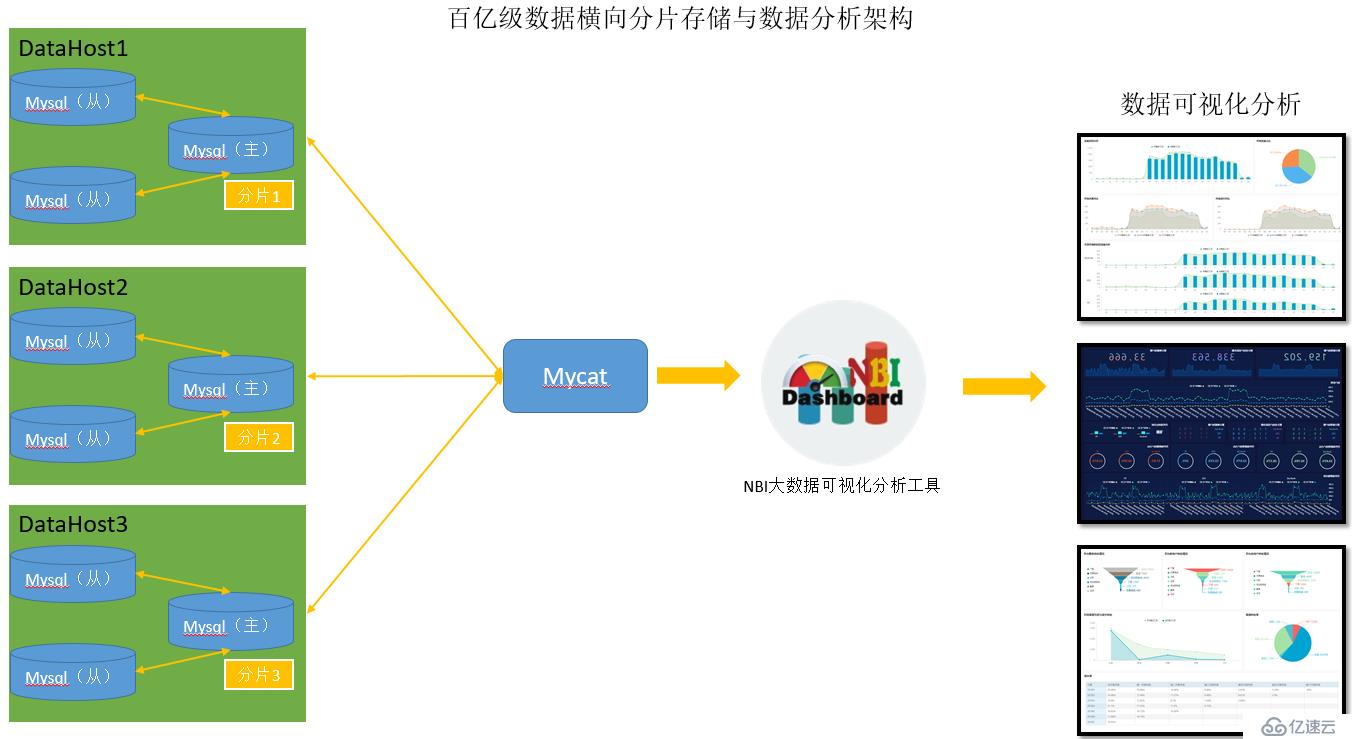
基于分布式关系型数据库,实现轻松应对百亿级数据分析场景方案
百亿级数据横向分片存储于数据分析架构
整体思路:
(1)利用字符集的分库分表规则,将百亿级数据横向分摊到不同的节点上;
(2)每个节点上实现一主多备,实现数据备份与读写分离,
(3)所有的写操作首先会在字符集中根据规则计算,路由到指定的节点上写操作,
(4)聚合查询字符集会分摊到各个节点上去计算之后,再基于节点的结果进行汇总处理;
(5)利用<强> NBI大数据可视化分析工具与字符集无缝连接;
(6)通过<强> NBI大数据可视化分析工具(http://nbi.easydatavis.com: 8033) 强提供的拖拽式分析,可以快速完成各类分析报告和百亿级数据,秒级响应的用户体验。