-
<李> scrapy的安装使用李
<李> scrapy架构李
<李>爬虫概念流程李
<李> scrapy项目开发流程李
<李> scrapy常用设置李
-
<李> scrapy的安装使用
scrapy的基本使用资料网站:https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/shell.html
-
<李>本文使用环境配置:这个主题+ pycharm + python3.7李
<李>在安装scrapy过程中遇到了比较多的坑,scrapy基于扭开发,直接安装scrapy无法安装,提示pip版本问题以及各种错误,pip安装,升级pip升级,安装你——祝辞pyOpenSSL——在扭曲——祝辞scrapy由于源是国外的站点,可能访问失败,下载过程也比较慢,推荐直接访问官方网站直接把.whl包直接下载下来,通过终端安装更便捷。运行过程还需要win32api,直接安装pypiwin32李
<李>使用命令李
李
<代码> 1。在终端输入scrapy命令可以查看可用命令 用法: scrapy & lt; command>[选项][arg游戏) 可用命令: 台运行快速的基准测试 拿取使用Scrapy下载一个URL genspider生成新的蜘蛛使用预定义的模板 runspider运行一个独立的蜘蛛(没有创建一个项目) 设置被设置值 shell交互刮控制台 startproject创建新项目 版本打印Scrapy版本 在浏览器视图中打开URL,因为被Scrapy
-
<李>
scrapy架构
-
<李>架构图
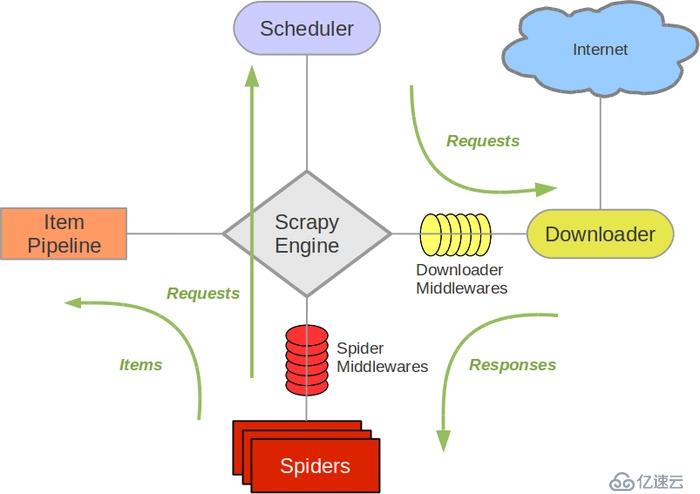 ?进程scrapy。蜘蛛类,里面的方法可以覆盖。
?进程scrapy。蜘蛛类,里面的方法可以覆盖。
<代码>进口scrapy
从. .项目导入DoubanItem
类DoubanSpider (scrapy.Spider):
name=' douban_mv '
allowed_domains=(“movie.douban.com”)
start_urls=(“https://movie.douban.com/top250”)
def解析(自我,反应):
movie_list=response.xpath ("//div [@class='文章']//ol李[@class=' grid_view ']////div [@class='物品']”)
在movie_list电影:
项=DoubanItem ()
项目(“serial_number”)=movie.xpath (’。//div [@class="图片"]/em/text()的).extract_first ()
项目(“movie_name”)=movie.xpath (’。//div [@class="高清"]//跨度/text ()”) .extract_first ()
介绍=movie.xpath (’。//div [@class=" bd "]/p/text()的).extract ()
项目(“介绍”)=";" . join(介绍)。替换(“”).replace (' \ n ',”) .strip (“;”)
项目(“星”)=movie.xpath (’。//div [@class="明星"]/跨度[@class=" rating_num "]/text()的).extract_first ()
项目(“核定”)=movie.xpath (’。//div [@class="明星"]/跨度[4]/text () ') .extract_first ()
项目(“desc)=movie.xpath (’。//p [@class="引用"]/跨度[@class=" inq "]/text()的).extract_first ()
收益项目
“下一页”实现翻页操作
链接=response.xpath('//跨度[@class=跋乱桓觥盷/联系/@href”) .extract_first ()
如果链接:
收益率response.follow(链接,回调=self.parse) scrapy的使用