在使用碧玉报表工具制作报表时,常常会遇到数据来自多个数据源的情况,通常的做法是使用主子报表或者使用javabean作为数据源。使用主子报表通常会增加报表设计的复杂度,而使用javabean做数据源,则需要一个javabean类来支持,并且为了在设计报表时能够看到数据,还要为ireport提供一个静态方法,该方法用于返回上面定义javabean的一个结果集。
显然,上面这两种办法都不太方便,本文将提供一种更加简便的方法,那就是通过集算器来解决ireport中的多数据源问题,并进一步提ireport的高性能。我们将以JasperReport5.6.0开发环境为例进行介绍。
ireport中如何使用多数据源
报表项目中,常常会出现报表源数据来自不同数据库的情况,例如同一应用系统的数据库负载太大,不得已分成多个数据库,就像是最常见的销售系统数据分成当前库和历史库,一部分数据存于数据库一部分数据存于文件等。
在多数据源的数据库类型方面,报表工具可能连接同样类型的数据库,比如都是mysql或者甲骨文;也可能是不同的类型,如txt, csv或者Excel等。
我们的例子中,报表数据一部分来自mysql数据库,一部分来自文本文件。
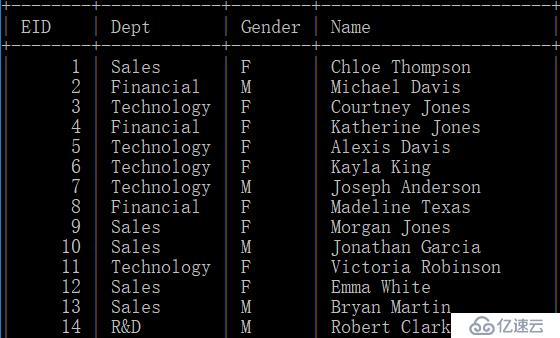
其中,mysql数据库的员工表存储开斋节为1 - 100000的数据,内容如下:
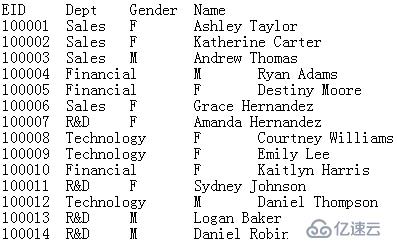
而数据。txt文件中存储开斋节为100001 - 101000的数据,内容如下:
我们的任务是在“中制作一张报表,查看员工表和emp。txt文件合并后的所有数据。这一需求通过集算器协助ireport可以轻松实现。集算器使用我们称之为结构化处理语言(结构化过程语言,简称SPL),具体的SPL代码如下:
<强> <强> 1 =连接(mysql) <强> 2 =A1。query@x (“select * from employee”) <强> 3 =文件(“F: \ \文件\ \ emp.txt”) .import@t() <强> 4 =(A2、A3) .conj() <强> 5 返回A4
A1:创建数据源连接,连接mysql数据源。
A2:在mysql数据源中查询员工表中的数据,并返回查询结果。
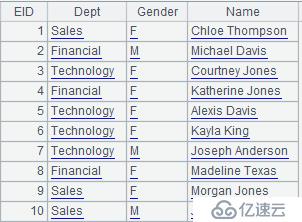
A3:读取文件emp。txt的内容。
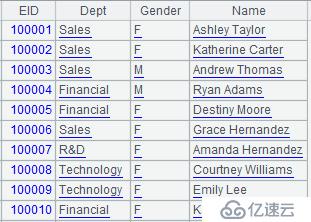
A4:合并A2和A3数据。
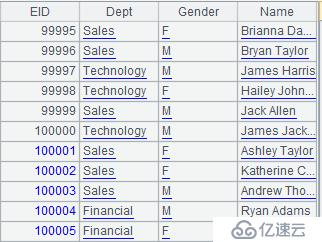
A4:将A4合并后的结果返回给报表。
为了在报表中呈现计算结果,我们需要将以上SPL代码存为文件员工。dfx,然后就可以利用集算器对外提供的JDBC接口调用这个脚本了。
在报表工具中通过建立JDBC数据源引入集算器脚本的方法和调用存储过程一样,在碧玉的SQL设计器中可以用<代码>调用员工()来调用。具体步骤在《JasperReport调用SPL脚本》一文中有详细的描述。
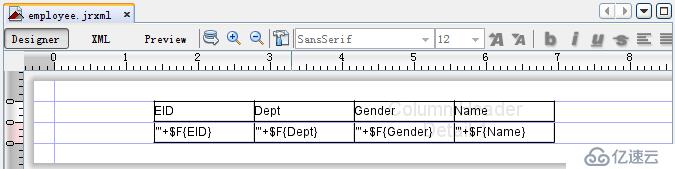
然后,我们可以在“中设计一个最简单的报表员工。jrxml格式,模板如下:
预览后可以直接看到报表结果了:
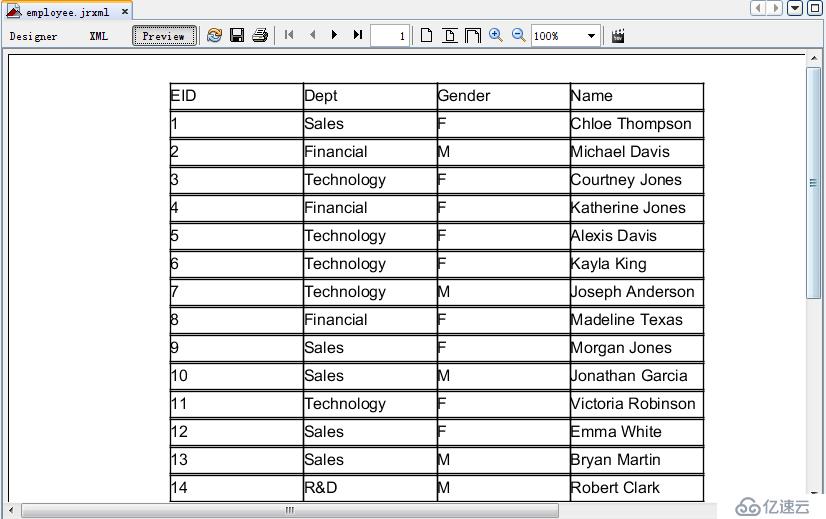
显然,这个过程相比传统的主子报表或者javabean方法要简单不少,更重要的是,计算逻辑非常清晰,集成方式也几乎没有任何学习成本。
性能优化
在解决了基本的功能需求后,我们还可以进一步将焦点关注到性能方面。报表项目中,常常需要将多个表连接查询,在这些被连接的表中,可能会包含海量的数据,例如:将雇员表和订单表通过共有字段员工编号连接起来,以便查看某些订单的销售人员的信息。显然,订单表会随着时间的推移不断增长,最终带来严重的系统负担。
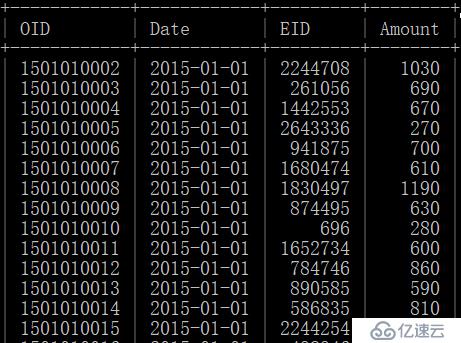
下面例子中的报表数据一部分来自mysql数据库的员工表,一部分来自mysql数据库的销售表。
其中,雇员表存储开斋节为1 - 3000000的雇员数据,内容如下:
而订单数据销售表则存储了万76条数据,而且持续增加。其中的数据内容样例如下: