本期内容:
1解密火花流运行机制
2解密火花流架构
一切不能进行实时流处理的数据都是无效的数据。在流处理时代,SparkStreaming有着强大吸引力,而且发展前景广阔,加之火花的生态系统,流可以方便调用其他的诸如SQL, MLlib等强大框架,它必将一统天下。
火花流运行时与其说是火花核心上的一个流式处理框架,不如说是火花核心上的一个最复杂的应用程序。如果可以掌握火花流这个复杂的应用程序,那么其他的再复杂的应用程序都不在话下了。这里选择火花流作为版本定制的切入点也是大势所趋。
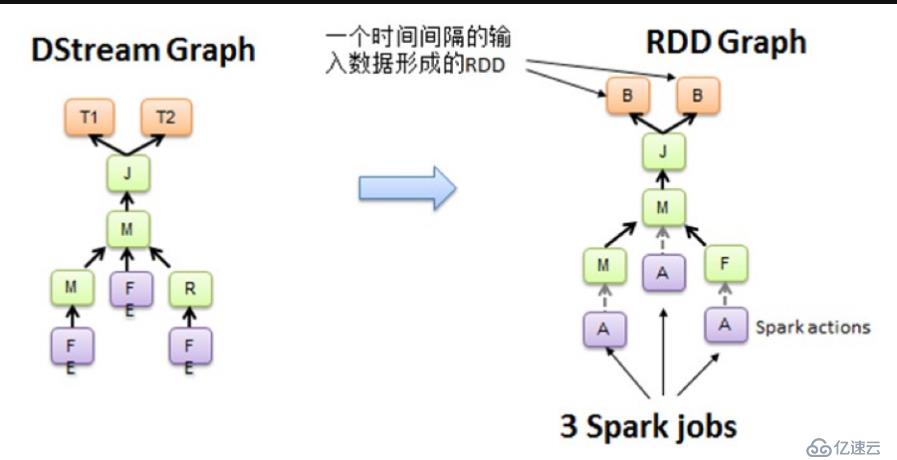
从这里可以看的出,DStream就是火花流的核心,就想火花核心的核心是抽样,它也有依赖和计算。更为关键的是下面的代码: