1 HDFS概述
1.1 HDFS产出背景及定义
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统.HDFS只是分布式文件管理系统中的一种。
HDFS (Hadoop分布式文件系统),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
1.2 HDFS优缺点
优点:
-
<李>高容错性
-
<李>数据自动保存多个副本。它通过增加副本的形式,提高容错性李
<李>某一个副本丢失以后,它可以自动恢复李
李
缺点:
-
<李>不适合低延时数据访问,比如毫秒级的存储数据李
<李>无法高效的对大量小文件进行存储李
<李>不支持并发写入,文件随机修改李
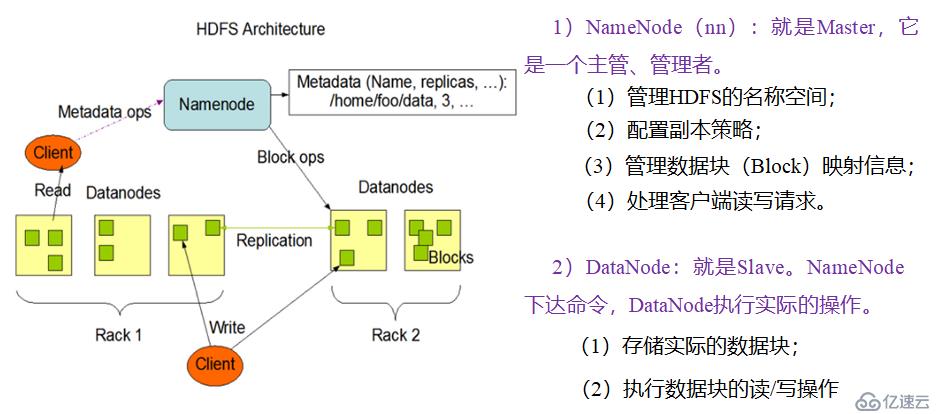
1.3 HDFS组成架构

1.4 HDFS文件块大小
HDFS中的文件在物理上是分块存储(块),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2。x版本中是128,老版本中是64。
如果寻址时间为100毫秒,即查找目标块的时间是100 ms。
寻址时间与传输时间的比例为100:1为最佳状态,因此传输时间为1。
目前磁盘的传输速率大概在100 mb/s,取个整大概就是128 mb。
2 HDFS的壳操作
(1) - help:输出这个命令参数
(2) - ls:显示目录信息
(3) mkdir:在HDFS上创建目录
(4) -moveFromLocal:从本地剪切粘贴到HDFS
(5) -appendToFile:追加一个文件到已经存在的文件末尾
(6)猫:显示文件内容
(7) chgrp chmod,乔恩:Linux文件系统中的用法一样,修改文件所属权限
(8) -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
(9) -copyToLocal:从HDFS拷贝到本地
(10) - cp:从HDFS的一个路径拷贝到HDFS的另一个路径
(11) mv:在HDFS目录中移动文件
(12) -:等同于copyToLocal,就是从HDFS下载文件到本地
(13) -getmerge:合并下载多个文件,比如HDFS的目录/user/djm/测试下有多个文件:日志。1、log.2 log.3…
(14)——:等同于copyFromLocal
(15)多边形:显示一个文件的末尾
(16) rm:删除文件或文件夹
(17)删除文件夹:删除空目录
(18)在:统计文件夹的大小信息
(19) -setrep:设置HDFS中文件的副本数量
3 HDFS客户端操作
<代码类="语言java ">包com.djm.hdfsclient;
进口org.apache.hadoop.conf.Configuration;
进口org.apache.hadoop.fs。*;
进口org.junit.After;
进口org.junit.Before;
进口org.junit.Test;
进口java.io.IOException;
进口java.net.URI;
公开课HdfsClient {
文件系统的文件系统=零;
@Before
公共空间init () {
尝试{
文件系统=FileSystem.get (URI.create (“hdfs://hadoop102:9000”),新配置(),“djm”);
}捕捉(IOException e) {
e.printStackTrace ();
}捕捉(InterruptedException e) {
e.printStackTrace ();
}
}/* *
*上传文件
*/@Test
公共空间put () {
尝试{
文件系统。copyFromLocalFile(新路径(“C: \ \ \ \ \ \用户管理员桌面\ \ Hadoop入门。海事”),新路径("/"));
}捕捉(IOException e) {
e.printStackTrace ();
}
}/* *
*下载文件
*/@Test
公共空间下载(){
尝试{//useRawLocalFileSystem表示是否开启文件校验
文件系统。copyToLocalFile (false,新的路径("/Hadoop入门。海事”),新路径(“C: \ \ \ \ \ \用户管理员桌面\ \ Hadoop入门1. md”),真的);
}捕捉(IOException e) {
e.printStackTrace ();
}
}/* *
*删除文件
*/@Test
公共空间删除(){
尝试{//递归表示是否递归删除
fileSystem.delete(新路径“/Hadoop入门。海事”),真的);
}捕捉(IOException e) {
e.printStackTrace ();
}
}/* *
*文件重命名
*/@Test
公共空间重命名(){
尝试{
文件系统。重命名(新路径“/tmp”),新路径(/temp));
}捕捉(IOException e) {
e.printStackTrace ();
}
}/* *
*查看文件信息
*/@Test
公共空间ls () {
尝试{
RemoteIteratorHadoop之HDFS