1、HBase的数据存储原理
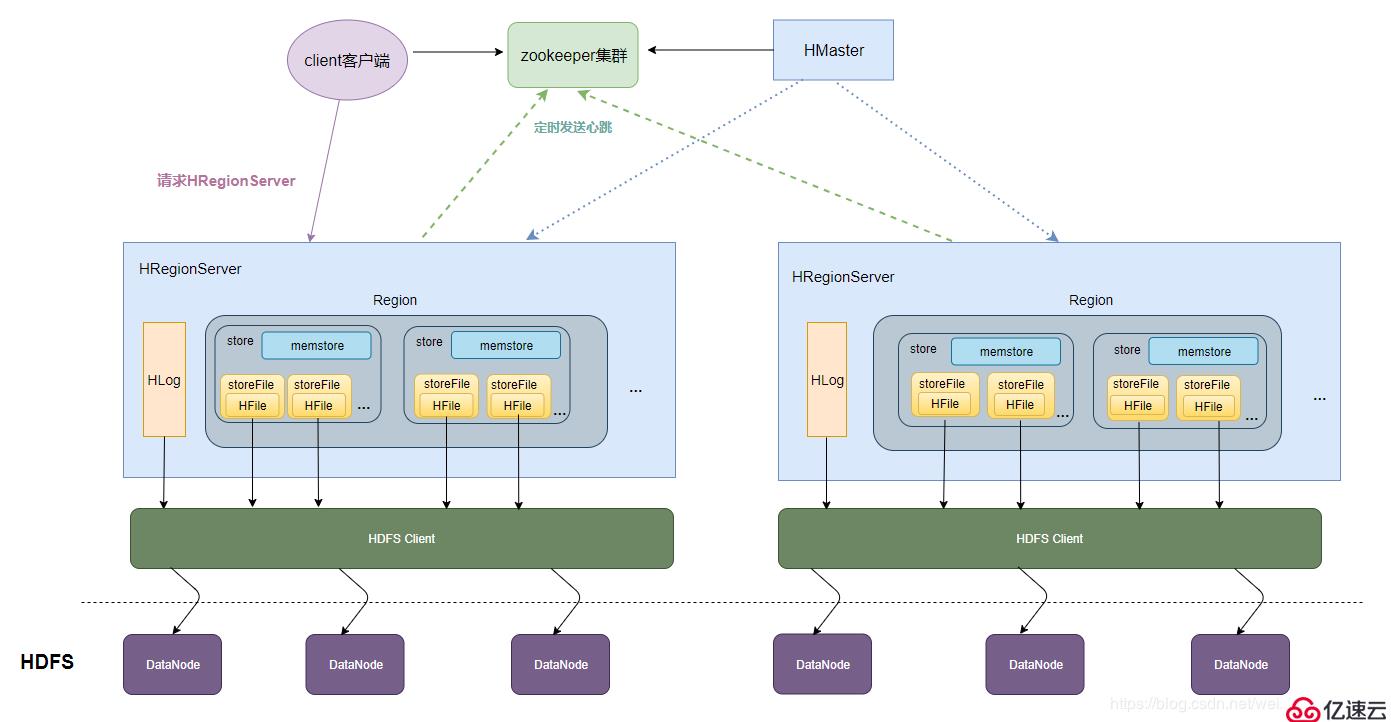
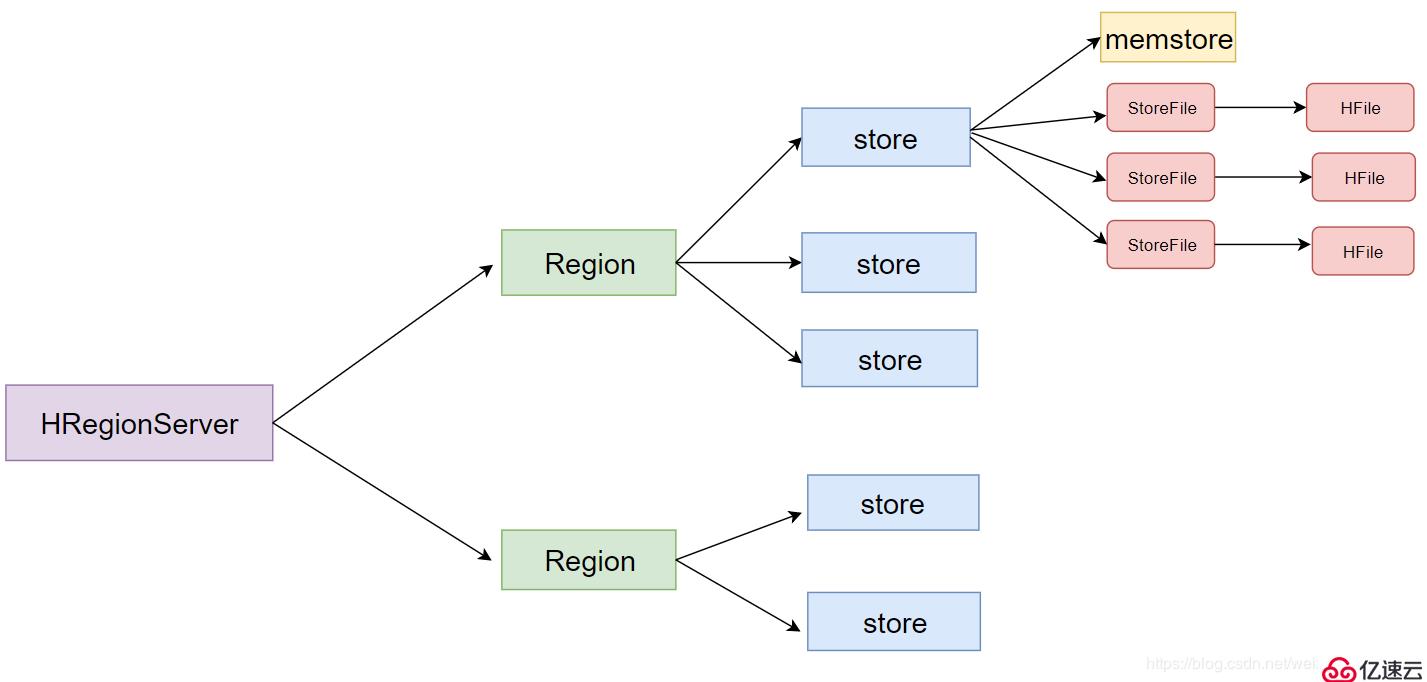
- 一个HRegionServer会负责管理很多个region
- 一个*region包含很多个store
- 一个列族就划分成一个store**
- 如果一个表中只有1个列族,那么每一个region中只有一个store
- 如果一个表中有N个列族,那么每一个region中有N个store
- 一个store里面只有一个memstore
- memstore是一块内存区域,写入的数据会先写入memstore进行缓冲,然后再把数据刷到磁盘
一个store里面有很多个StoreFile, 最后数据是以很多个HFile这种数据结构的文件保存在HDFS上
- StoreFile是HFile的抽象对象,如果说到StoreFile就等于HFile
- 每次memstore刷写数据到磁盘,就生成对应的一个新的HFile文件出来
2、HBase读数据流程
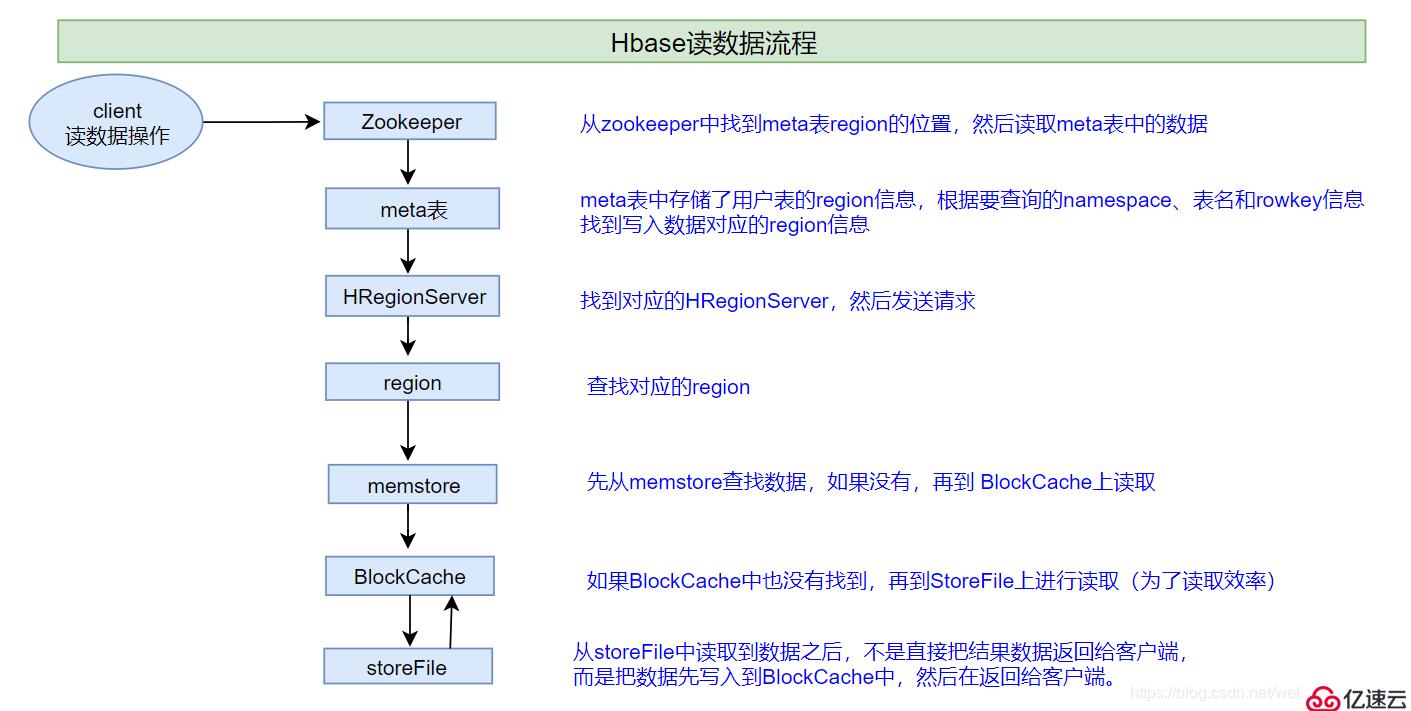
说明:HBase集群,只有一张meta表,此表只有一个region,该region数据保存在一个HRegionServer上
- 1、客户端首先与zk进行连接;从zk找到meta表的region位置,即meta表的数据存储在某一HRegionServer上;客户端与此HRegionServer建立连接,然后读取meta表中的数据;meta表中存储了所有用户表的region信息,我们可以通过
scan 'hbase:meta'来查看meta表信息 - 2、根据要查询的namespace、表名和rowkey信息。找到写入数据对应的region信息
- 3、找到这个region对应的regionServer,然后发送请求
- 4、查找并定位到对应的region
- 5、先从memstore查找数据,如果没有,再从BlockCache上读取
- HBase上Regionserver的内存分为两个部分
- 一部分作为Memstore,主要用来写;
- 另外一部分作为BlockCache,主要用于读数据;
- 6、如果BlockCache中也没有找到,再到StoreFile上进行读取
- 从storeFile中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。
3. HBase写数据流程

- <李>
1,客户端首先从zk找到元表的区域位置,然后读取元表中的数据,元表中存储了用户表的地区信息
<李>2,根据名称空间,表名和rowkey信息。找到写入数据对应的地区信息
<李>3,找到这个地区对应的regionServer,然后发送请求
<李>4,把数据分别写到HLog(提前写日志)和memstore各一份
<李>5, memstore达到阈值后把数据刷到磁盘,生成storeFile文件
<李> 6,删除HLog中的历史数据李<代码>补充: HLog(提前写日志): ,,也称为细胞膜意为提前写日志,类似mysql中的binlog,用来做灾难恢复时用,HLog记录数据的所有变更,一旦数据修改,就可以从日志中进行恢复。