
介绍
本篇文章给大家分享的是有关Python中怎么实现一个数据透视表,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
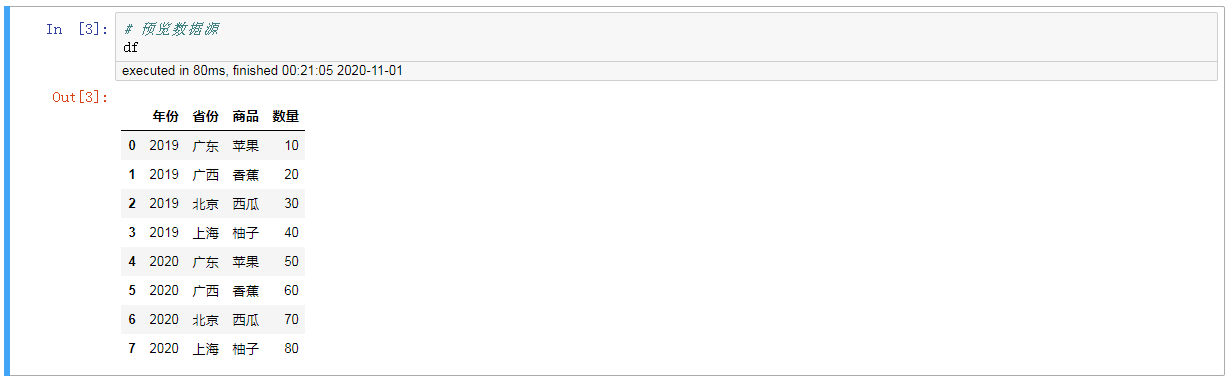
1。预览数据源
#,预览数据源 df
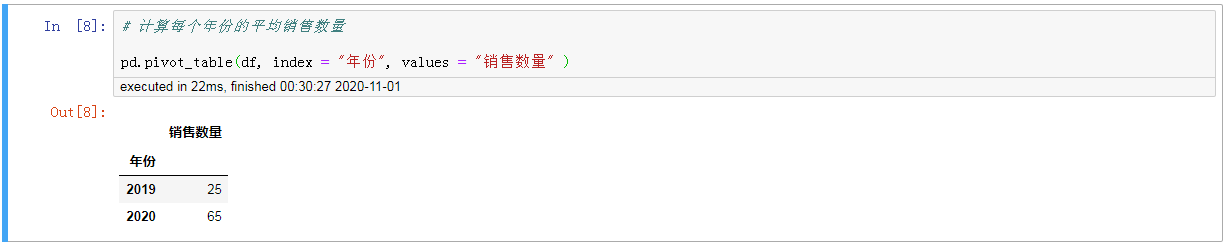
2只计算每个年份的平均销售数量
#,计算每个年份的平均销售数量 pd.pivot_table (df, index =,“年份“,,values =,“销售数量,,)
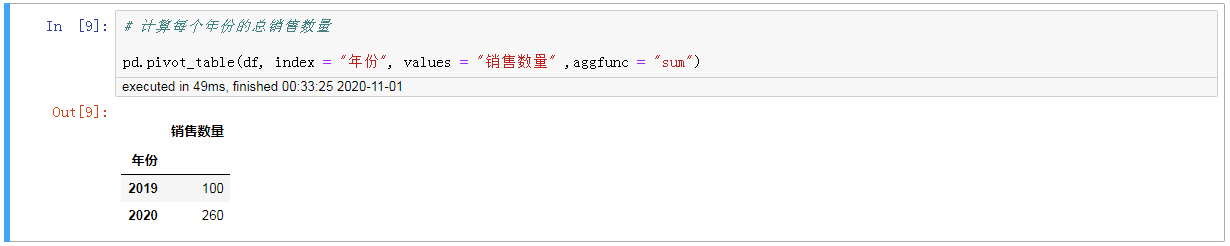
3只计算每个年份的总销售数量
#,计算每个年份的总销售数量 pd.pivot_table (df, index =,“年份“,,values =,“销售数量,,,aggfunc =,“sum")
4只;计算各个省份各种商品的总销售数量
#,计算各个省份各种商品的总销售数量 pd.pivot_table (df, index =,“省份“,,columns =,“商品,,,values =,“销售数量,,,aggfunc =,“sum")

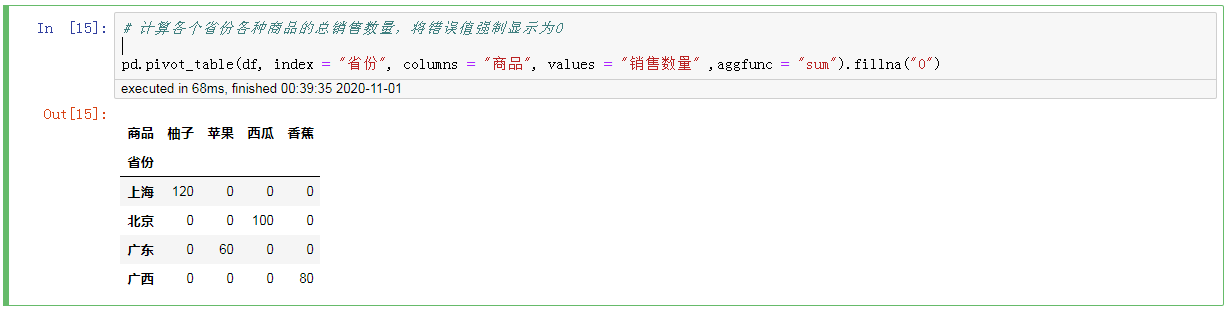
5只,计算各个省份各种商品的总销售数量,将错误值强制显示为0
#,计算各个省份各种商品的总销售数量,将错误值强制显示为0 pd.pivot_table (df, index =,“省份“,,columns =,“商品,,,values =,“销售数量,,,aggfunc =,“sum") .fillna (“0”)
6只计算各个省份各种商品的总销售数量,将错误值强制显示为0。添加合计行与列
#,计算各个省份各种商品的总销售数量,将错误值强制显示为0。添加合计行与列 pd.pivot_table (df, index =,“省份“,,columns =,“商品,,,values =,“销售数量,,,aggfunc =,“sum", margins =, True) .fillna (“0”)

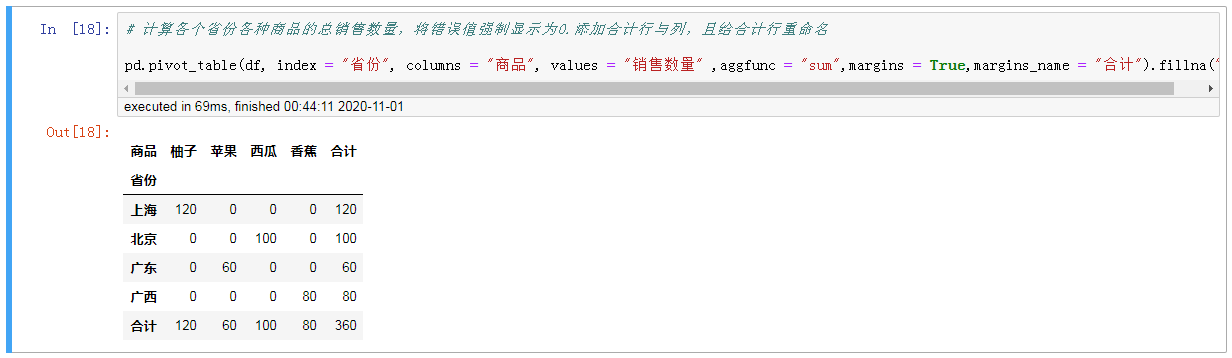
7只#计算各个省份各种商品的总销售数量,将错误值强制显示为0。添加合计行与列,且给合计行重命名
#,计算各个省份各种商品的总销售数量,将错误值强制显示为0。添加合计行与列,且给合计行重命名 pd.pivot_table (df, index =,“省份“,,columns =,“商品,,,values =,“销售数量,,,aggfunc =,“sum", margins =,真的,margins_name =,“合计“).fillna (“0”)
以上就是Python中怎么实现一个数据透视表,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注行业资讯频道。




