1,区域拆分机制
- <李>
区域中存储的是大量的rowkey数据,当区域中的数据条数过多的时候,直接影响查询效率。当地区过大的时候。hbase会拆分地区,这也是hbase的一个优点。
<李>hbase的地区分割策略一共有以下几种:
<李>1, <强> ConstantSizeRegionSplitPolicy
- <李> 0.94版本前默认切分策略李
当地区大小大于某个阈值(hbase.hregion.max.filesize=10 g)之后就会触发切分,一个地区等分为2个区域。
- <李>但是在生产线上这种切分策略却有相当大的弊端:切分策略对于大表和小表没有明显的区分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事。如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的地区,这对于集群的管理,资源使用,故障转移来说都不是一件好事。
2, <强> IncreasingToUpperBoundRegionSplitPolicy
- <李>
0.94版本~ 2.0版本默认切分策略
<李>切分策略稍微有点复杂,总体看和ConstantSizeRegionSplitPolicy思路相同,一个地区的大小大于设置阈值就会触发切分。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和地区所属表在当前regionserver上的地区个数有关系。李李
<>区域分割的计算公式是:regioncount ^ 3 128 2,当地区达到该大小的时候进行分裂
例如:
第一次分裂:1 ^ 3 256=256 mb
第二次分割:2 ^ 3 256=2048 mb
第三次分裂:3 ^ 3 256=6912 mb
第四次分裂:4 ^ 3 256=16384 mb的祝辞10 gb,因此取较小的值10 gb
后面每次分裂的大小都是10 gb了
3 <强> SteppingSplitPolicy
- <李>
2.0版本默认切分策略
<李>这种切分策略的切分阈值又发生了变化,相比IncreasingToUpperBoundRegionSplitPolicy简单了一些,依然和待分裂区域所属表在当前regionserver上的地区个数有关系,如果个地区数等于1,切分阈值为冲洗大小* 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表,小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小区域,而是适可而止。
, <强> KeyPrefixRegionSplitPolicy
- <李>根据rowKey的前缀对数据进行分组,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在进行区域分割的时候会分到相同的地区中。
, <强> DelimitedKeyPrefixRegionSplitPolicy
- <李>保证相同前缀的数据在同一个区域中,例如rowKey的格式为:userid_eventtype eventid,指定的分隔符为,则分割的的时候会确保用户标识相同的数据在同一个地区中。
- <李>不启用自动拆分,需要指定手动拆分
2,地区合并机制
1.1地区合并说明
- <李>地区的合并不是为了性能,,而是出于维护的目的。 <李>比如删除了大量的数据,这个时候每个地区都变得很小,存储多个地区就浪费了,这个时候可以把地区合并起来,进而可以减少一些地区服务器节点
1.2如何进行地区合并
1.2.1通过合并类冷合并地区
- <李>
执行合并前,==需要先关闭hbase集群==
<李>创建一张hbase表:<代码类=" language-ruby ">创建& # 39;测试# 39;& # 39;info1& # 39;,分裂=比;[& # 39;1000 & # 39;& # 39;2000 & # 39;,& # 39;3000 & # 39;]
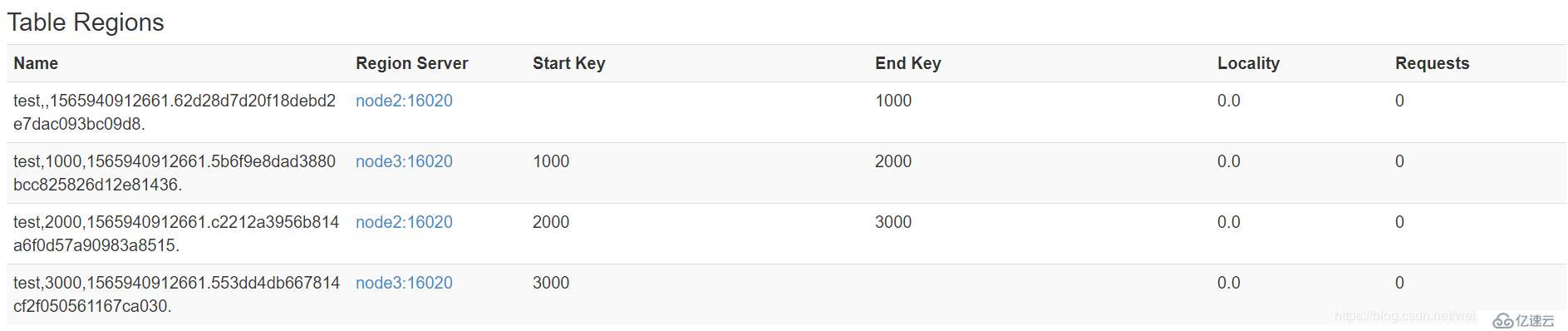
- <李>查看表地区
 <李>
<李> 需求:
需要把测试表中的2个地区数据进行合并:
测试,1565940912661.62 d28d7d20f18debd2e7dac093bc09d8。
测试,1000年1565940912661.5 b6f9e8dad3880bcc825826d12e81436。
这里通过org.apache.hadoop.hbase.util。合并类来实现,不需要进入hbase壳,直接执行(==需要先关闭hbase集群==):
hbase org.apache.hadoop.hbase.util。合并测试,测试,1565940912661.62 d28d7d20f18debd2e7dac093bc09d8。1000年测试,1565940912661.5 b6f9e8dad3880bcc825826d12e81436。李李