
介绍 Python主要用来做什么 #, - *安康;编码:UTF-8 - * -
#小猪短租爬取
import 请求
得到bs4 import BeautifulSoup
import json
def get_xinxi(我):=,url & # 39; http://cd.xiaozhu.com/search-duanzufang-p%d-0/& # 39; %我=,,html requests.get (url)=,,soup BeautifulSoup (html.content)
,#获取地址
,dizhis=soup.select (& # 39;, div 祝辞,a 祝辞,跨度# 39;)
,#获取价格=,,prices soup.select (& # 39;, span.result_price& # 39;)
,#获取简单信息=,,ems soup.select (& # 39;, div 祝辞,em # 39;)
,datas =[]
,for dizhi、价格、em 拷贝zip (dizhis、价格、ems):
data=https://www.yisu.com/zixun/{才能
的价格:price.get_text (),
“信息”:em.get_text () .replace ('/n ',”)。替换(“”),
“地址:dizhi.get_text ()
}
print (json.dumps(数据).decode (“unicode-escape”))
i=1
虽然(我<12):
get_xinxi(我)
我+ 1= soup =, BeautifulSoup (html.content) for dizhi,价格,em 拷贝zip (dizhis、价格、ems): json.dumps(数据).decode (“unicode-escape") # page_list 祝辞,ul 祝辞,李:nth-of-type(1),在一个
这篇文章主要介绍了如何在Python中输出\ u编码并将其转换成中文,小编觉得不错,现在分享给大家,也给大家做个参考,一起跟随小编来看看吧!
Python主要应用于:1,网络开发;2、数据科学研究;3,网络爬虫;4、嵌入式应用开发,5日游戏开发;6桌面应用开发。
爬取了12页的信息
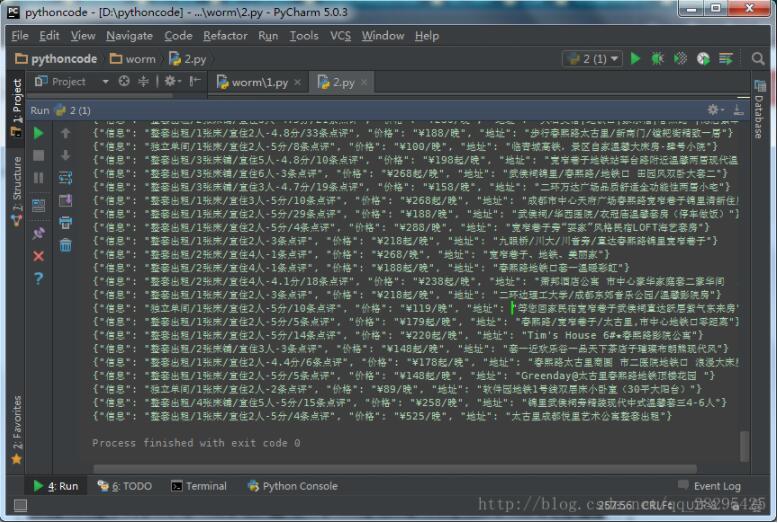
<强>小结:
压注意的是
创建汤
多个值的为赋值
字典的输出编码问题
如果想获取每个个详细信息可以获取其href属性值
,然后获取其属性值获得(“href # 39;)获取每个的详情信息在解析页面获取想要的信息加在数据字典中
以上就是小编为大家收集整理的如何在Python中输出\ u编码并将其转换成中文,如何觉得网站的内容还不错,欢迎将网站推荐给身边好友。




