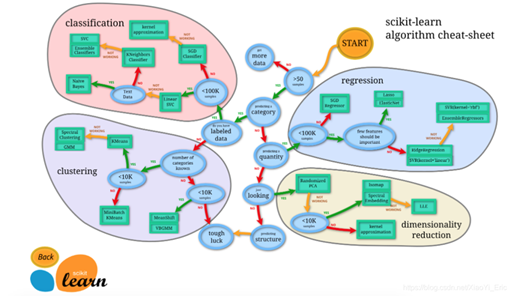
Scikit-learn (Sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(回归),降维(降维),分类(分类),聚类(集群)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法.Sklearn具有以下特点:
<李> 简单高效的数据挖掘和数据分析工具
<李> 让每个人能够在复杂环境中重复使用
<李> 建立NumPy, Scipy, MatPlotLib之上
2. Sklearn安装
Sklearn安装要求<代码> Python(祝辞=2.7或祝辞=3.3),<代码> NumPy(祝辞=1.8.2),<代码> Scipy(祝辞=0.13.3)> pip安装- u Scikit-learn>
3. Sklearn通用学习模式
Sklearn中包含众多机器学习方法,但各种学习方法大致相同,我们在这里介绍Sklearn通用学习模式。首先引入需要训练的数据,Sklearn自带部分数据集,也可以通过相应方法进行构造,<代码> 4。Sklearn数据集> MatPlotLib> 得到sklearn import 数据集#引入数据集,Sklearn包含众多数据集
得到sklearn.model_selection import train_test_split #将数据分为测试集和训练集
得到sklearn.neighbors import KNeighborsClassifier #利用邻近点方式训练数据
# # # # # #引入数据
虹膜=datasets.load_iris() #引入虹膜鸢尾花数据,虹膜数据包含4个特征变量
iris_X=iris.data #特征变量
iris_y=iris.target #目标值
X_train、X_test y_train y_test=train_test_split (iris_X、iris_y test_size=0.3) #利用train_test_split进行将训练集和测试集进行分开,test_size占30%
打印(y_train) #我们看到训练数据的特征值分为3类
& # 39;& # 39;& # 39;
(0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1
,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2,2
,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2
,2,2)
,& # 39;& # 39;& # 39;
# # # # # #训练数据
然而,=KNeighborsClassifier() #引入训练方法
knn.fit (X_train y_train) #进行填充测试数据进行训练
# # # # # #预测数据
打印(knn.predict (X_test) #预测特征值
& # 39;& # 39;& # 39;
(1,1,1,0,2,2,1,1,1,0,0,0,2,2,0,1,2,2,0,- 1,0,0,0,0,0,0,2,- 1,0,0,0,1,0,2,0,2,0
,1,2,- 1,0,0,1,0,2)
& # 39;& # 39;& # 39;
打印(y_test) #真实特征值
& # 39;& # 39;& # 39;
(1,1,1,0,1,2,1,1,1,0,0,0,2,2,0,1,2,2,0,- 1,0,0,0,0,0,0,2,- 1,0,0,0,1,0,2,0,2,0
,1,2,- 1,0,0,1,0,2)
& # 39;& # 39;& # 39; 4。Sklearn数据集
Sklearn提供一些标准数据,我们不必再从其他网站寻找数据进行训练,例如我们上面用来训练的<代码> load_iris> load_sample_images() 来引入图片。

除了Sklearn提供的一些数据之外,还可以自己来构造一些数据帮助我们学习。
得到sklearn import 数据集#引入数据集
#构造的各种参数可以根据自己需要调整
X, y=datasets.make_regression (n_samples=100, n_features=1, n_targets=1,噪音=1)
# # #绘制构造的数据# # #
import matplotlib.pyplot as plt
plt.figure ()
plt.scatter (X, y)
plt.show () 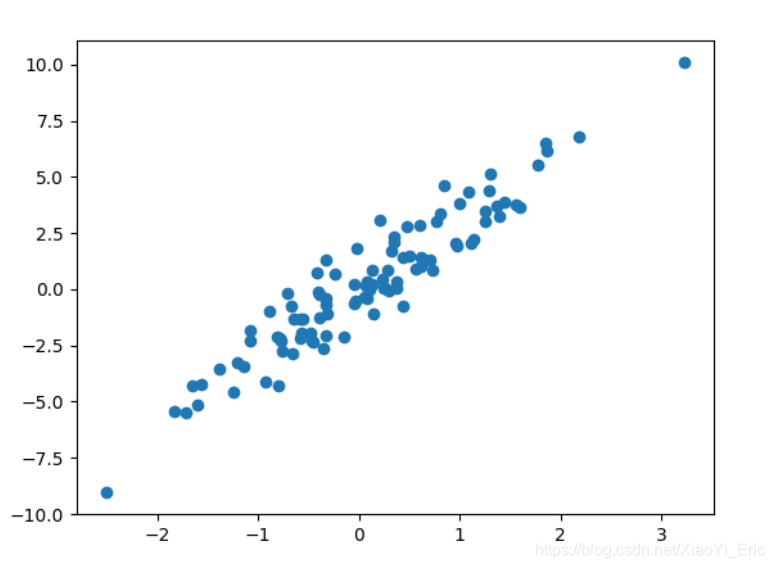
5。Sklearn模型的属性和功能
数据训练完成之后得到模型,我们可以根据不同模型得到相应的属性和功能,并将其输出得到直观结果。假如通过线性回归训练之后得到线性函数





