
介绍 PageOfficeCtrl poCtrl=new PageOfficeCtrl(请求);
poCtrl.setServerPage (request.getContextPath () +“/poserver.zz");//打开词文档
poCtrl.webOpen(“文档/test.doc" OpenModeType.docNormalEdit,“张佚名“); , & lt; div 比;
,,,& lt; %=poCtrl.getHtmlCode (“PageOfficeCtrl1") %比;
& lt;才能/div> var txt =, . getelementbyid (“PageOfficeCtrl1") .GetWordItemsConent ();
这篇文章将为大家详细讲解有关Java获取词文档的条目化内容的方法,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
在开发网络办公系统或文档系统时,PageOffice组件是众所周知的在线处理微软word/ppt/excel文档的强大工具,它对这个词文档的各种处理在API层面进行了封装,屏蔽了办公室VBA接口的复杂性,而又不失VBA的强大功能,在此要分享的正是PageOffice封装的一个很强大的功能:获取词文档的条目化内容。在一个包含了文档处理功能的办公系统里,用户出于各种原因,希望能通过程序自动分析字文档中每个章节的内容也是一种合理的需求,而PageOffice为实现此功能提供的接口也非常简单,废话少说,直接看代码:
PageOffice具体的集成过程在此略过…(详细看PageOffice Java开发包中的安装说明)
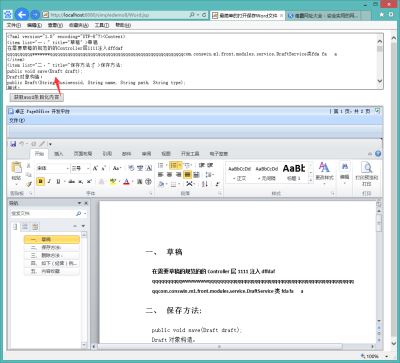
1。调用PageOffice在线打开一个包含了章节层次的词文档,比如:测试。医生
2。在打开词文件的页面(比如:单词。jsp)里显示文件的区域添加PageOffice的代码:
3。文件在线打开之后,通过按钮或其他方式调用执行下面的js,变量三种就可以获取到文档条目化的内容:
4。运行效果:
关于“Java获取词文档的条目化内容的方法”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看的到。




