
介绍 df.sample(压裂=1).reset_index(滴=True) 得到sklearn.utils import 洗牌
df =,洗牌(df) df.iloc [np.random.permutation (len (df))]
这篇文章主要介绍了Python中熊猫怎样洗牌打乱数据,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获、下面让小编带着大家一起了解一下。
在Python里面,使用熊猫里面的DataFrame来存放数据的时候想要把数据集进行洗牌会许多的方法,具体如下:
应用情景:
我们有下面以个DataFrame
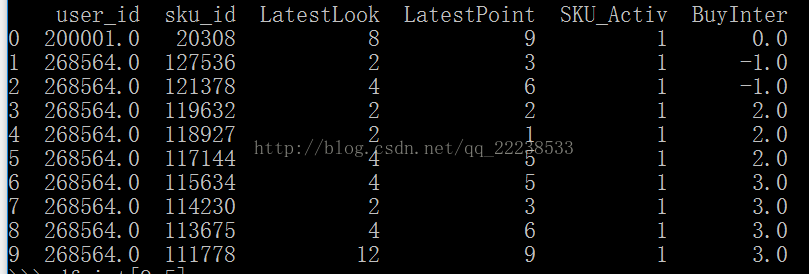 df.sample(压裂=1)
df.sample(压裂=1)
这样对可以对df进行洗牌。其中参数压裂是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么压裂=0.3。
有时候,我们可能需要打混后数据集的指数(索引)还是按照正常的排序。我们只需要这样操作
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -分割线- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
其实,sklearn(机器学习的库)中也有洗牌的方法。
另外,numpy库中也有进行洗牌的方法(不建议)
感谢你能够认真阅读完这篇文章,希望小编分享的“Python中熊猫怎样洗牌打乱数据”这篇文章对大家有帮助,同时也希望大家多多支持,关注行业资讯频道,更多相关知识等着你来学习!




