
介绍 <李> <李> dc =, zip(日期、时间背景下,大敌;;链接)
,,,pdf =, pd.DataFrame(直流,列=[& # 39;日期# 39;,,& # 39;hotsearch& # 39;,, & # 39;链接# 39;]) enging =, create_engine (“mysql + pymysql://根:123456 @localhost: 3306/webo ? charset=utf8")
pdf.to_sql (name=& # 39;信息# 39;,,=输入,监狱,if_exists=癮ppend") 得到selenium.webdriver import Chrome, ChromeOptions
import 时间
得到sqlalchemy import create_engine
import pandas as pd
def get_data ():
,,,url =, r" https://s.weibo.com/top/summary",, #,微博的地址
,,,option =, ChromeOptions ()
,,,option.add_argument(& # 39;——无头# 39;)
,,,option.add_argument (“——no-sandbox")
,,,browser =, Chrome(选项=选项)
,,,browser.get (url)
,,,all =, browser.find_elements_by_xpath (& # 39;//* [@ id=皃l_top_realtimehot"]/表/身体/tr/td[2]/一个# 39;)
,,,context =, (i.text for 小姐:拷贝所有)
,,,links =, (i.get_attribute (& # 39; href # 39;), for 小姐:拷贝所有)
,,,date =, time.strftime (“Y % - % - % d % H_ % M_ % S",, time.localtime ())
,,,dates =, []
,,,for 小姐:拷贝范围(len(上下文)):
,,,,,,,dates.append(日期)
,,,#,打印(len(日期),len(上下文),日期,上下文)
,,,dc =, zip(日期、时间背景下,大敌;;链接)
,,,pdf =, pd.DataFrame(直流,列=[& # 39;日期# 39;,,& # 39;hotsearch& # 39;,, & # 39;链接# 39;])
,,,#,pdf.to_sql (name=,,=输入,监狱,if_exists=癮ppend")
,,,return pdf
def w_mysql (pdf):
,,,试一试:
,,,,,,,enging =, create_engine (“mysql + pymysql://根:123456 @localhost: 3306/webo ? charset=utf8")
,,,,,,,pdf.to_sql (name=& # 39;信息# 39;,,=输入,监狱,if_exists=癮ppend")
,,,除了:
,,,,,,,印刷(& # 39;出错了& # 39;)
if __name__ ==, & # 39; __main__ # 39;:
,,,xx =, get_data ()
,,,w_mysql (xx)
这篇文章主要介绍了python如何实现爬取微博热搜存入Mysql,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获、下面让小编带着大家一起了解一下。
<强> python爬取微博热搜存入Mysql
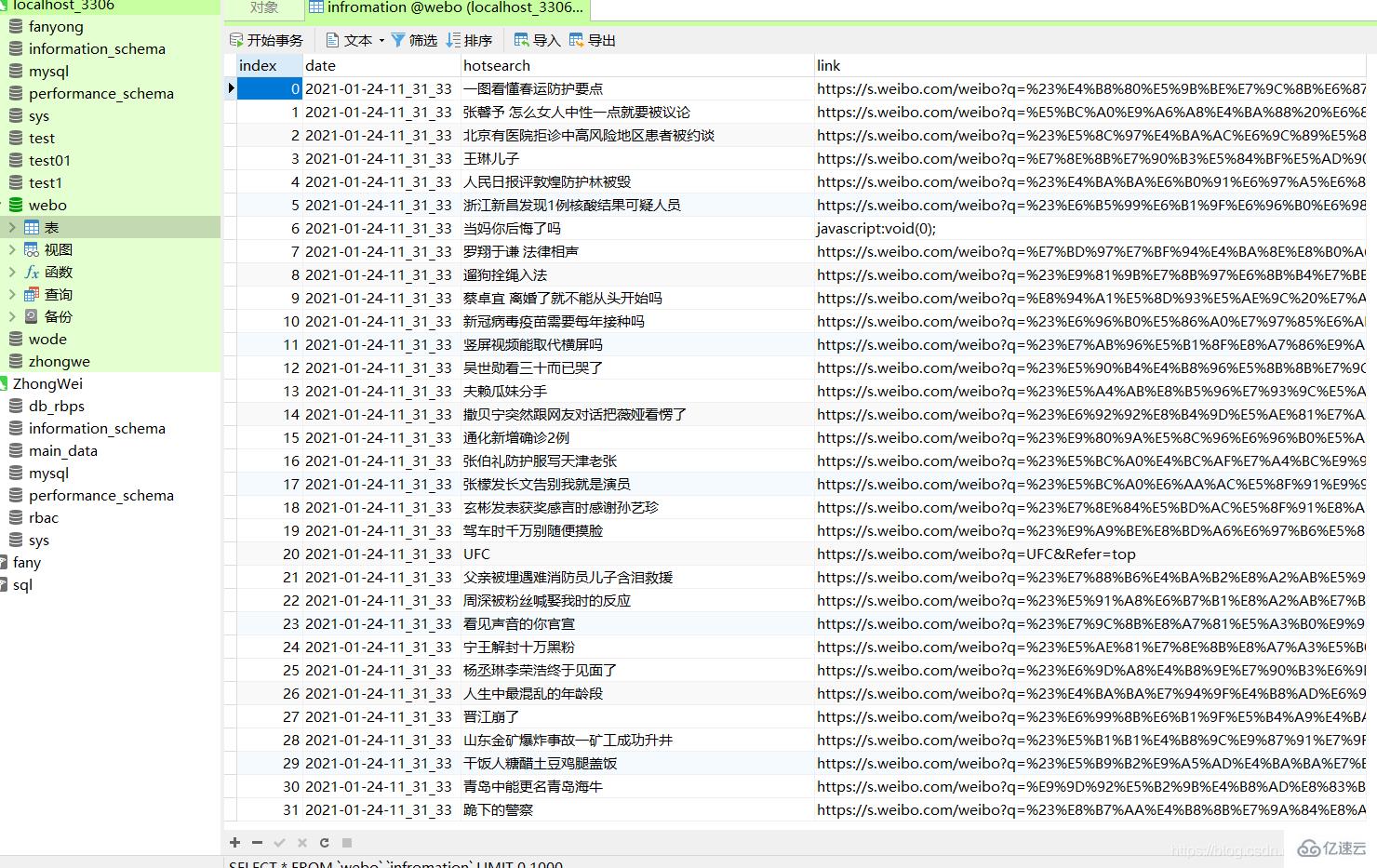
最终的效果
<李>使用的库
<李>目标分析
<李>一:得到数据
<李>二:链接数据库
<李>总代码
<强>最终的效果
废话不多少,直接上图
 import 请求
得到selenium.webdriver import Chrome, ChromeOptions
import 时间
得到sqlalchemy import create_engine
import pandas as pd
import 请求
得到selenium.webdriver import Chrome, ChromeOptions
import 时间
得到sqlalchemy import create_engine
import pandas as pd
<强>目标分析
这是微博热搜的链接:点我可以到目标网页
 all =, browser.find_elements_by_xpath (& # 39;//* [@ id=皃l_top_realtimehot"]/表/身体/tr/td[2]/一个# 39;),,#得到所有数据
时间=context [i.text for 小姐:拷贝;c),, #,得到标题内容
,,,links =, (i.get_attribute (& # 39; href # 39;), for 小姐:拷贝;c),, #,得到链接
all =, browser.find_elements_by_xpath (& # 39;//* [@ id=皃l_top_realtimehot"]/表/身体/tr/td[2]/一个# 39;),,#得到所有数据
时间=context [i.text for 小姐:拷贝;c),, #,得到标题内容
,,,links =, (i.get_attribute (& # 39; href # 39;), for 小姐:拷贝;c),, #,得到链接
然后我们再使用zip函数,将日期、上下文、链接合并
zip函数是将几个列表合成一个列的表,并且按指数对分列表的数据合并成一个元组,这个可以生产熊猫对象。
其中日期可以使用时间模块获得
<强>二:链接数据库
这个很容易
<强>总代码




