
这篇文章给大家分享的是有关libco是怎样支撑巨大数据信息量的的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
ibco是微信后台大规模使用的c/c++协程库,2013年至今稳定运行在微信后台的数万台机器上.libco在2013年的时候作为腾讯六大开源项目首次开源,我们最近做了一次较大的更新,同步更新在github.com/tencent/libco上.libco支持后台敏捷的同步风格编程模式,同时提供系统的高并发能力。
libco支持的特性
无需侵入业务逻辑,把多进程,多线程服务改造成协程服务,并发能力得到百倍提升;
支持CGI框架,轻松构建web服务(新),
支持gethostbyname, mysqlclient, ssl等常用第三库(新),
可选的共享栈模式,单机轻松接入千万连接(新),
完善简洁的协程编程接口
-类pthread接口设计,通过co_create, co_resume等简单清晰接口即可完成协程的创建与恢复;——类线程的协程私有变量,协程间通信的协程信号量co_signal(新);——非语言级别的λ实现,结合协程原地编写并执行后台异步任务(新);– 基于epoll/kqueue实现的小而轻的网络框架,基于时间轮盘实现的高性能定时器;
libco产生的背景
早期微信后台因为业务需求复杂多变、产品要求快速迭代等需求,大部分模块都采用了半同步半异步模型。接入层为异步模型,业务逻辑层则是同步的多进程或多线程模型,业务逻辑的并发能力只有几十到几百。随着微信业务的增长,系统规模变得越来越庞大,每个模块很容易受到后端服务/网络抖动的影响。
异步化改造的选择
为了提升微信后台的并发能力,一般的做法是把现网的所有服务改成异步模型。这种做法工程量巨大,从框架到业务逻辑代码均需要做一次彻底的改造,耗时耗力而且风险巨大。于是我们开始考虑使用协程。
但使用协程会面临以下挑战:
业界协程在c/c++环境下没有大规模应用的经验;
如何控制协程调度;
如何处理同步风格的API调用,如Socket、mysqlclient等;
如何处理已有全局变量、线程私有变量的使用;
最终我们通过libco解决了上述的所有问题,实现了对业务逻辑非侵入的异步化改造。我们使用libco对微信后台上百个模块进行了协程异步化改造,改造过程中业务逻辑代码基本无修改。至今,微信后台绝大部分服务都已是多进程或多线程协程模型,并发能力相比之前有了质的提升,而libco也成为了微信后台框架的基石。
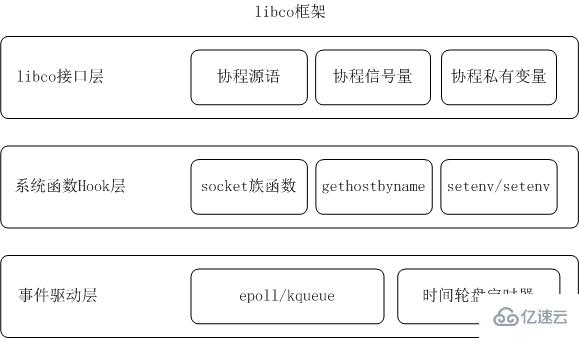
libco框架
libco在框架分为三层,分别是接口层、系统函数Hook层以及事件驱动层。
同步风格API的处理
对于同步风格的API,主要是同步的网络调用,libco的首要任务是消除这些等待对资源的占用,提高系统的并发性能。一个常规的网络后台服务,我们可能会经历connect、write、read等步骤,完成一次完整的网络交互。当同步的调用这些API的时候,整个线程会因为等待网络交互而挂起。
虽然同步编程风格的并发性能并不好,但是它具有代码逻辑清晰、易于编写的优点,并可支持业务快速迭代敏捷开发。为了继续保持同步编程的优点,并且不需修改线上已有的业务逻辑代码,libco创新地接管了网络调用接口(Hook),把协程的让出与恢复作为异步网络IO中的一次事件注册与回调。当业务处理遇到同步网络请求的时候,libco层会把本次网络请求注册为异步事件,本协程让出CPU占用,CPU交给其它协程执行。libco会在网络事件发生或者超时的时候,自动的恢复协程执行。
大部分同步风格的API我们都通过Hook的方法来接管了,libco会在恰当的时机调度协程恢复执行。
千万级协程支持
libco默认是每一个协程独享一个运行栈,在协程创建的时候,从堆内存分配一个固定大小的内存作为该协程的运行栈。如果我们用一个协程处理前端的一个接入连接,那对于一个海量接入服务来说,我们的服务的并发上限就很容易受限于内存。为此,libco也提供了stackless的协程共享栈模式,可以设置若干个协程共享同一个运行栈。同一个共享栈下的协程间切换的时候,需要把当前的运行栈内容拷贝到协程的私有内存中。为了减少这种内存拷贝次数,共享栈的内存拷贝只发生在不同协程间的切换。当共享栈的占用者一直没有改变的时候,则不需要拷贝运行栈。




