
今天就跟大家聊聊有关使用Python爬虫怎么爬取小红书,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
首先,我们打开之前大家配置好的查尔斯。
我们来简单抓包一下小红书小程序(注意这里是小程序,不是应用)
不选择应用的原因是,小红书的应用有点难度,参照网上的一些思路,还是选择了小程序
1,通过查尔斯抓包对小程序进行分析
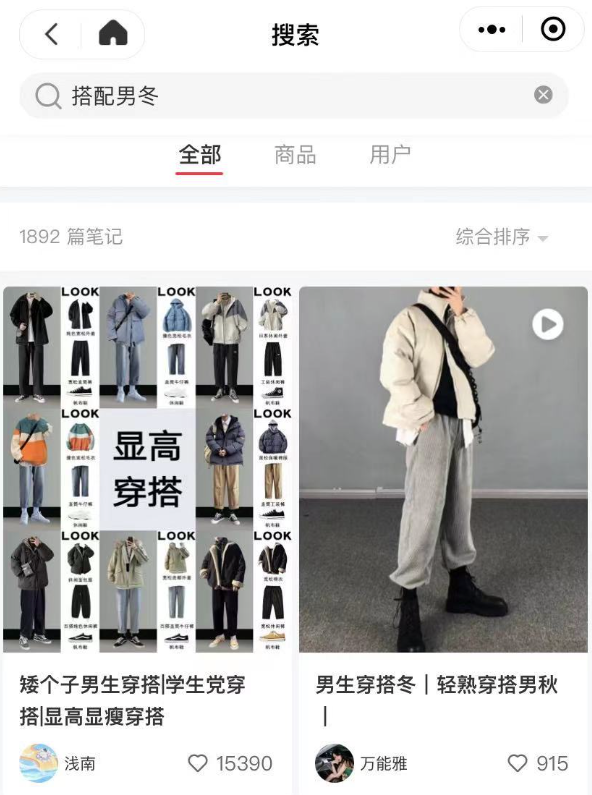
这两个玩意,一直在变化,而且不知道从何获取。
所以
2,使用mitmproxy来进行抓包
其实通过查尔斯抓包,整体的抓取思路我们已经清晰
就是获取到“authorization"和“x-sign"两个参数,然后对url进行得到请求
这里用到的mitmproxy,其实和查尔斯差不多,都是抓包工具
但是mitmproxy能够跟Python一起执行
这就舒服很多啊
简单给大家举例子
在mitmproxy中提供这样的方法给我们,我们可以通过请求对象截取到请求头中的url,饼干,主机,方法,港口,计划等属性
这不正是我们想要的吗?
我们直接截取“authorization"和“x-sign"这两个参数
然后往标题里填入
整个就完成了。
以上是我们整个的爬取思路,下面给大家讲解一下代码怎么写
其实代码写起来并不难
首先,我们必须截取到搜索api的流,这样我们才能够对其进行获取信息
我们通过判断流的请求里面是否存在搜索api的url
来确定我们需要抓取的请求
通过上述代码,我们就能够把最关键的三个参数拿到手了,接下来就是一些普通的解析json了。
最终,我们可以拿到自己想要的数据了
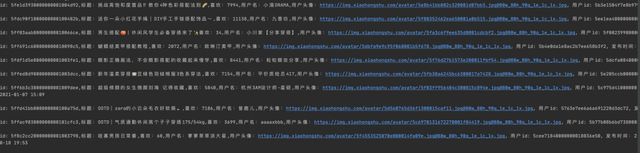 “https://www.xiaohongshu.com/discovery/item/", +, str (id)
“https://www.xiaohongshu.com/discovery/item/", +, str (id)
 看完上述内容,你们对使用Python爬虫怎么爬取小红书有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注行业资讯频道,感谢大家的支持。
看完上述内容,你们对使用Python爬虫怎么爬取小红书有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注行业资讯频道,感谢大家的支持。




