介绍
如何正确的使用oracle索引?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
1。随机数据生成代码分析
,为测试索引而准备的随机数据生成代码,先分析一下
select rownum as id,
,,,,& # 39;给史密斯# 39;| | trunc (dbms_random.value (0, 100)), as stu_name,
,,,,dbms_random.string (& # 39; x # 39;,, 20), stu_pwd,
,,,,to_char (add_months (sysdate, -DBMS_RANDOM.VALUE (100200)), +, rownum /, 24,/, 3600年,& # 39;yyyy-mm-dd hh34: mi: ss # 39;), as birthday
,,,,解码(,TRUNC (DBMS_RANDOM.VALUE(1、5)), 1 & # 39;湖南省& # 39;,2 & # 39;湖北省& # 39;,3 & # 39;江西省& # 39;,& # 39;北京市& # 39;),as 地址
,才能得到双
,,connect by level & lt;=, 100; ——先分析以下上面的代码
——伪列:,rownum
——,双,:测试表
——,| |字符串联接
- 1。测试生成100条记录,,连接level<=100:
——一个,利用Oracle特有的“连接”树形连接语法生成测试记录,“水平& lt;=100”表示要生成100记录;
——b,利用rownum虚拟列生成递增的整数数据;
——c,利用sysdate函数加一些简单运算来生成日期数据,本例中是每条记录的时间加1秒;
,,,,add_months (sysdate -DBMS_RANDOM.VALUE (100200)),用当前时间减去,至少100个月,最多200个月,来生成生日
d,利用dbms_random。值函数生成随机的数值型数据,都是双型,所以都加了trunc (,,)以截断小数位,本例中是生成0到100之间的随机整数;
- e,利用dbms_random.string函数生成随机的字符型数据,本例中是生成长度为20的随机字符串,字符串中可以包括字符或数字。
2。生成测试表及数据
, 2只正式生成100 w
drop table stu_test_100w;,——如果原来有,则先删除原来的表
,
——创建表及数据
create table stu_test_100w
作为
select rownum as id,
,,,,& # 39;给史密斯# 39;| | trunc (dbms_random.value (0, 99)), as stu_name,
,,,,dbms_random.string (& # 39; x # 39;,, 20), stu_pwd,
,,,,to_char (add_months (sysdate, -DBMS_RANDOM.VALUE (100200)), +, rownum /, 24,/, 3600年,& # 39;yyyy-mm-dd hh34: mi: ss # 39;), as birthday
,,,,解码(,TRUNC (DBMS_RANDOM.VALUE(1、5)), 1 & # 39;湖南省& # 39;,2 & # 39;湖北省& # 39;,3 & # 39;江西省& # 39;,& # 39;北京市& # 39;),as 地址
,才能得到双
,才能connect by level & lt;=, 1000000,,,,生成,100 w测试数据 ,,查看当前用户模式下所有的表,
select *,得到tab where tname=& # 39; STU_TEST_100W& # 39;;
——先执行一次查询,,注意查询所用的时间,此时并没有加入索引,
select *,得到stu_test_100w where stu_name=& # 39; smith23& # 39;; 执行结果:,
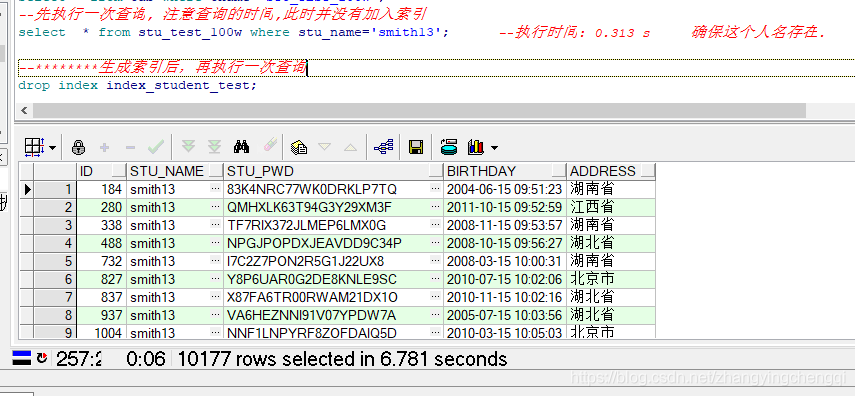
以上是没有用到索引时的执行用时,6.781秒只
下面创建索引后,再用同一查询来测试只
——* * * * * * * *生成索引后,再执行一次查询
drop index index_student_test;
,
create index index_student_test
提醒stu_test_100w (stu_name);,,,索引是针对某个表的某个列
,
——先执行一次查询,,注意查询的时间,此时加入了索引,
select *,得到stu_test_100w where stu_name=& # 39; smith23& # 39;; 
为什么用了索引后时间查询能还下降了呢? ? ? ?
<强>分析如下:,
,1. 索引生成的字段的值分存得太密集了,查看上面的代码会发现我们stu_name只生成在了,smith0 - 99之间,即只有100种的可能性,对于100 w数据则言,即每个名字都有约1 w个只
,2 .因为数据太密集了,所以以上查询的花的时间主要在1 w条数据的显示上,所以我们可以观察到不管是否用到了索引,都要共到6 - 7秒来显示结果只
,3只;那为什么用了索引还慢一些呢?,这就与索引的存储结构有关系了。甲骨文默认使用的是B树索引,当使用索引列查询时,查询必须先查看索引,通过索引去定位数据,而咱们的数据分布又比较密集,所以使用索引所导致的时间损耗要大于直接磁盘搜索的时间只,





