
介绍 import zlib
得到bs4 import BeautifulSoup
with 开放(r" C: \ \用户下载惠普\ \ 6024766870349300 _300_10.z",, & # 39; rb # 39;), as 鳍:=,,content fin.read ()
时间=btArr 中bytearray(内容)
xml=zlib.decompress (btArr) .decode (& # 39; utf - 8 # 39;)
时间=bs BeautifulSoup (xml、“xml")
b import zlib
得到bs4 import BeautifulSoup
import pandas as pd
import 请求
def get_data (tv_name tv_id):
,“““
,获取每集的tvid
,:param tv_name:集数,第1集,第2集…
,:param tv_id:每集的tvid
:返回:大敌;DataFrame,,最终的数据
,“““=,base_url & # 39; https://cmts.iqiyi.com/bullet/{}/{}/{} _300_{}还是z # 39;
,#新建一个只有表头的DataFrame=,,head_data pd.DataFrame(列=[& # 39;uid # 39; & # 39; contentsId& # 39;, & # 39;内容# 39;,& # 39;likeCount& # 39;])
,for 小姐:拷贝范围(20):=,,url base_url.format (tv_id [4: 2], tv_id [2], tv_id,我)
,打印(url)=,,res requests.get (url)
,if res.status_code ==, 200:
时间=btArr 才能;中bytearray (res.content),
xml才能=zlib.decompress (btArr) .decode (& # 39; utf - 8 # 39;), #,解压压缩文件
时间=bs 才能;BeautifulSoup (xml、“xml"), #, BeautifulSoup网页解析
data 才能=,pd.DataFrame(列=[& # 39;uid # 39; & # 39; contentsId& # 39;, & # 39;内容# 39;,& # 39;likeCount& # 39;])
数据才能[& # 39;uid # 39;],=, (i.text for 小姐:拷贝bs.findAll (& # 39; uid # 39;))
数据才能[& # 39;contentsId& # 39;],=, (i.text for 小姐:拷贝bs.findAll (& # 39; contentId& # 39;))
数据才能[& # 39;内容# 39;],=,(i.text for 小姐:拷贝bs.findAll(& # 39;内容# 39;))
数据才能[& # 39;likeCount& # 39;],=, (i.text for 小姐:拷贝bs.findAll (& # 39; likeCount& # 39;))
,其他的:
,打破=,,head_data pd.concat (head_data、数据,ignore_index =,真的)
,head_data [& # 39; tv_name& # 39;]=, tv_name
以前,return head_data 得到requests_html import HTMLSession, UserAgent
得到bs4 import BeautifulSoup
import 再保险
def get_tvid (url):
,“““
,获取每集的tvid
,:param url:请求网址
,:返回:str,,每集的tvid
,“““=,,session HTMLSession(), #创建HTML会话对象=,,user_agent UserAgent () .random #创建随机请求头=,,header {“User-Agent": user_agent}=,,res session.get (url,头=头)
,res.encoding=& # 39; utf - 8 # 39;=,,bs BeautifulSoup (res.text,“html.parser")
,pattern =re.compile (“。* tvid . * ? (\ d{16})。* ?“), #,定义正则表达式=,,text_list bs.find_all(文本=模式),#,通过正则表达式获取内容
,for t 拷贝范围(len (text_list)):=,,res_list pattern.findall (text_list [t])
,if not res_list:
,通过
,其他的:
时间=tvid 才能;res_list [0]
以前,return tvid
今天就跟大家聊聊有关利用Python怎么获取弹幕数据,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
输出

因此tvid只要获得就能轻松获取该电视剧的弹幕文件数据。
获取tvid
上文已通过tvid获取到了弹幕文件数据,那么如何获取tvid又变成了一个问题。莫急,我们继续分析。直接Ctrl + F搜索tvid
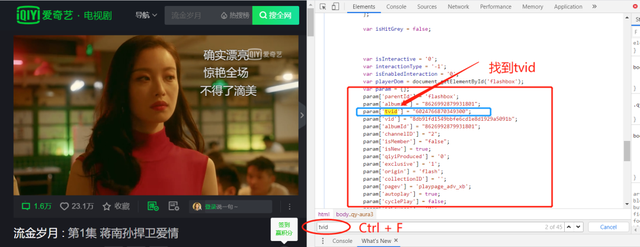
因此可以直接从返回结果中通过正则表达式获取tvid。
由此问题tvid。来每一集都有一个tvid,有多少集电视剧就可以获取多少个tvid。那么问题又来了:获取tvid时,是通过url发送请求,从返回结果中获取。而每一集的url又该如何获取呢。
获取每集url
通过元素选择工具定位到集数选择信息。通过硒模拟浏览器获取动态加载信息。
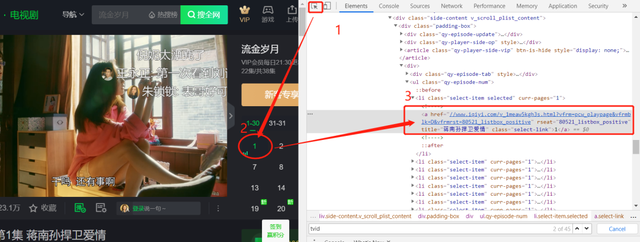
有小伙伴会说,可以直接直接从返回内容中获取此href网址啊,你可以自己动手尝试下。
云朵君尝试后得到的结果是href=癹avascript:无效(0);“rel=巴獠縩ofollow",因此解决这一问题的方法之一是运用硒模拟浏览器获取js动态加载信息。




