
使用Redis怎么实现高可用和持久化?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
高可用方案
虽然单台Redis的的性能很好,但是Redis的单节点并不能保证它不会挂了啊,毕竟单节点的Redis是有上限的,而且人家单节点又要读又要写,小身板扛不住咋办,所以为了保证高可用,一般都是做成集群。
主从(Master-Slave)
Redis官方是支持主从同步的,而且还支持从从同步,从从同步也可以理解为主从同步,只不过从从同步的主节点是另一个主从的从节点。
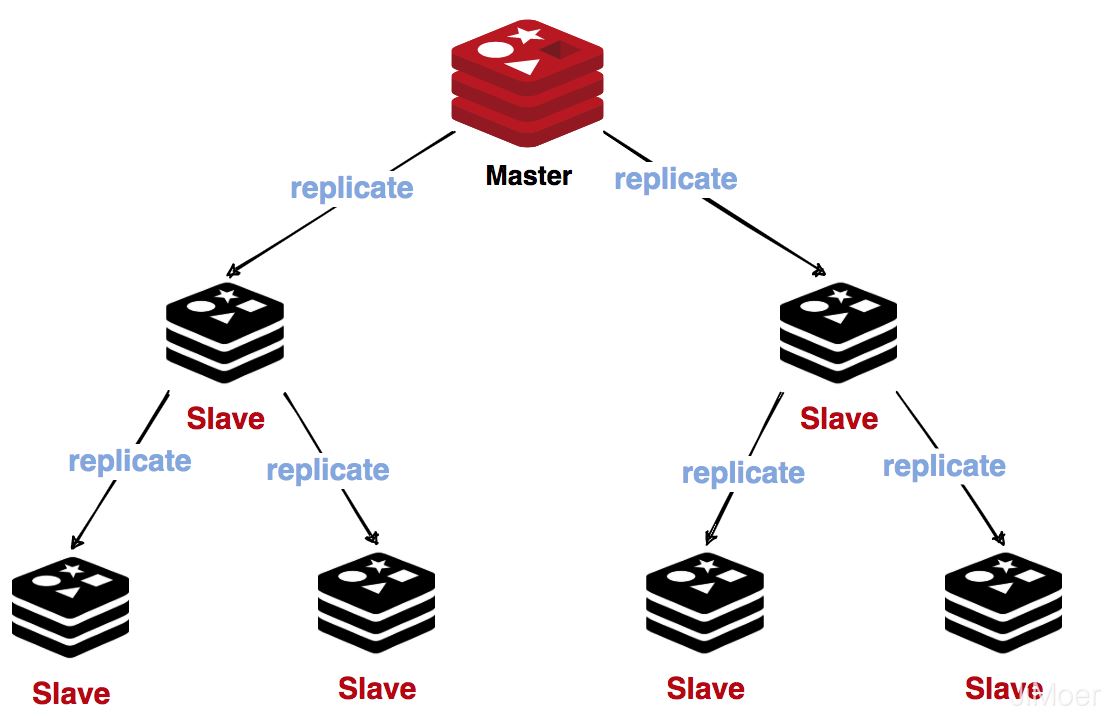
有了主从同步的集群,那么主节点就负责提供写操作,而从节点就负责支持读操作。
那么他们之间是如何进行数据同步的呢?
如果Slave(从节点)是第一次跟Master进行连接,
那么会首先会向Master发送同步请求
psync;主节点接收到同步请求,开始fork主子进程开始进行全量同步,然后生成RDB文件;
这个时候主节点同时会将新的写请求,保存到缓存区(buffer)中;
从节点接收到RDB文件后,先清空老数据,然后将RDB中数据加载到内存中;
等到从节点将RDB文件同步完成后再同步缓存区中的写请求。
数组被占满之后就会覆盖掉最早之前的数据。
所以如果由于网络或是其他原因,造成缓存区中的数据被覆盖了,那么当从节点处理完主节点的RDB文件后,就不得不又要进行一全量的RDB文件的复制,才能保证主从节点的数据一致。
如果不设置好合理的buffer区空间,是会造成一个RDB复制的死循环。
当主从间的数据同步完成之后,后面主节点的每次写操作就都会同步到从节点,这样进行增量同步了。
由于负载的不断上升就导致了主从之间的延时变大,所以就有了上面我说的从从同步了,主节点先同步到一部分从节点,然后由从节点去同步其他的从节点。
在Redis从2.8.18开始支持无盘复制,主节点通过套接字,一边遍历内存中的数据,一边让数据发送给从节点,从节点和之前一样,先将数据存储在磁盘文件中,然后再一次性加载。
另外由于主从同步是异步的,所以从Redis3.0之后出现了同步复制,就是通过wait命令来进行控制,wait命令有两个参数,第一个是从库数量,第二个是等待从库的复制时间,如果第二个参数设置为0,那么就是代表要等待所有从库都复制完才去执行后面的命令。
但是这样就会存在一个隐患,当网络异常后,wait命令会一直阻塞下去,导致Redis不可用。
哨兵(Sentinel)
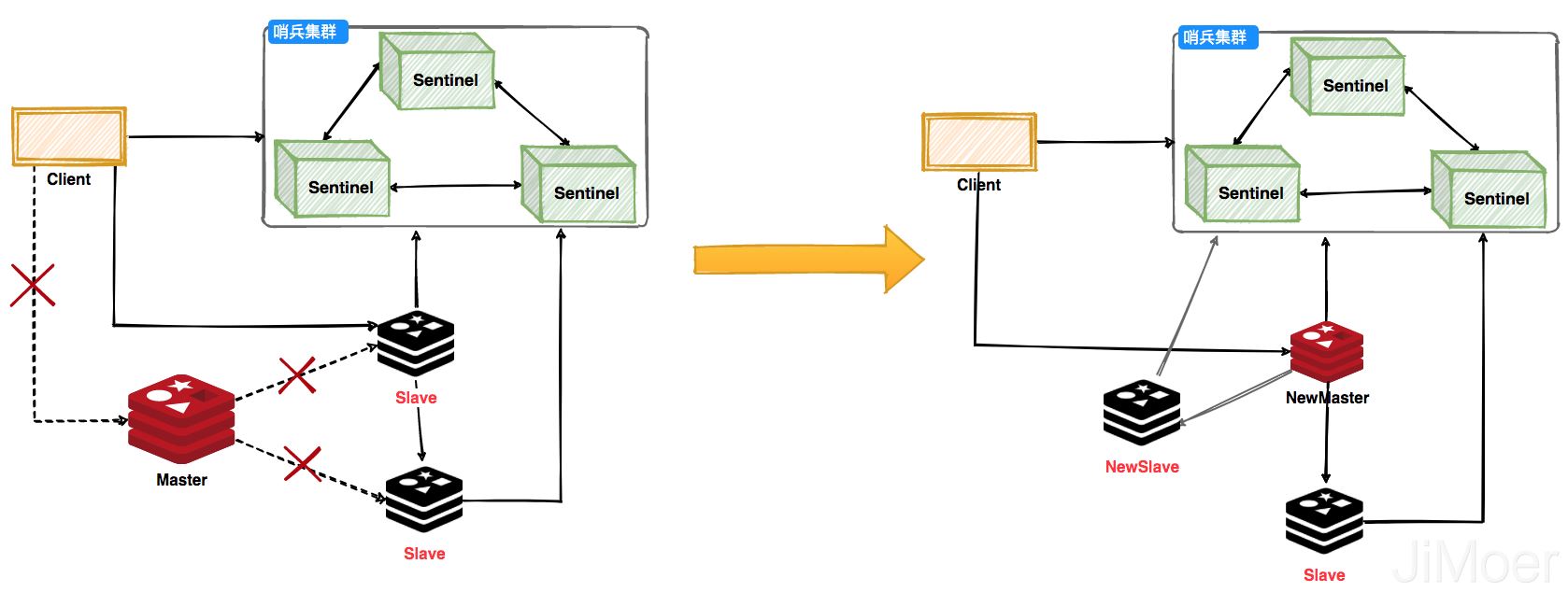
哨兵可以监控Redis集群的健康状态,当主节点挂掉之后,选举出新的主节点。客户端在使用Redis的时候会先通过Sentinel来获取主节点地址,然后再通过主节点来进行数据交互。当主节点挂掉之后,客户端会再次向Sentinel获取主节点,这样客户端就可以无感知的继续使用了。
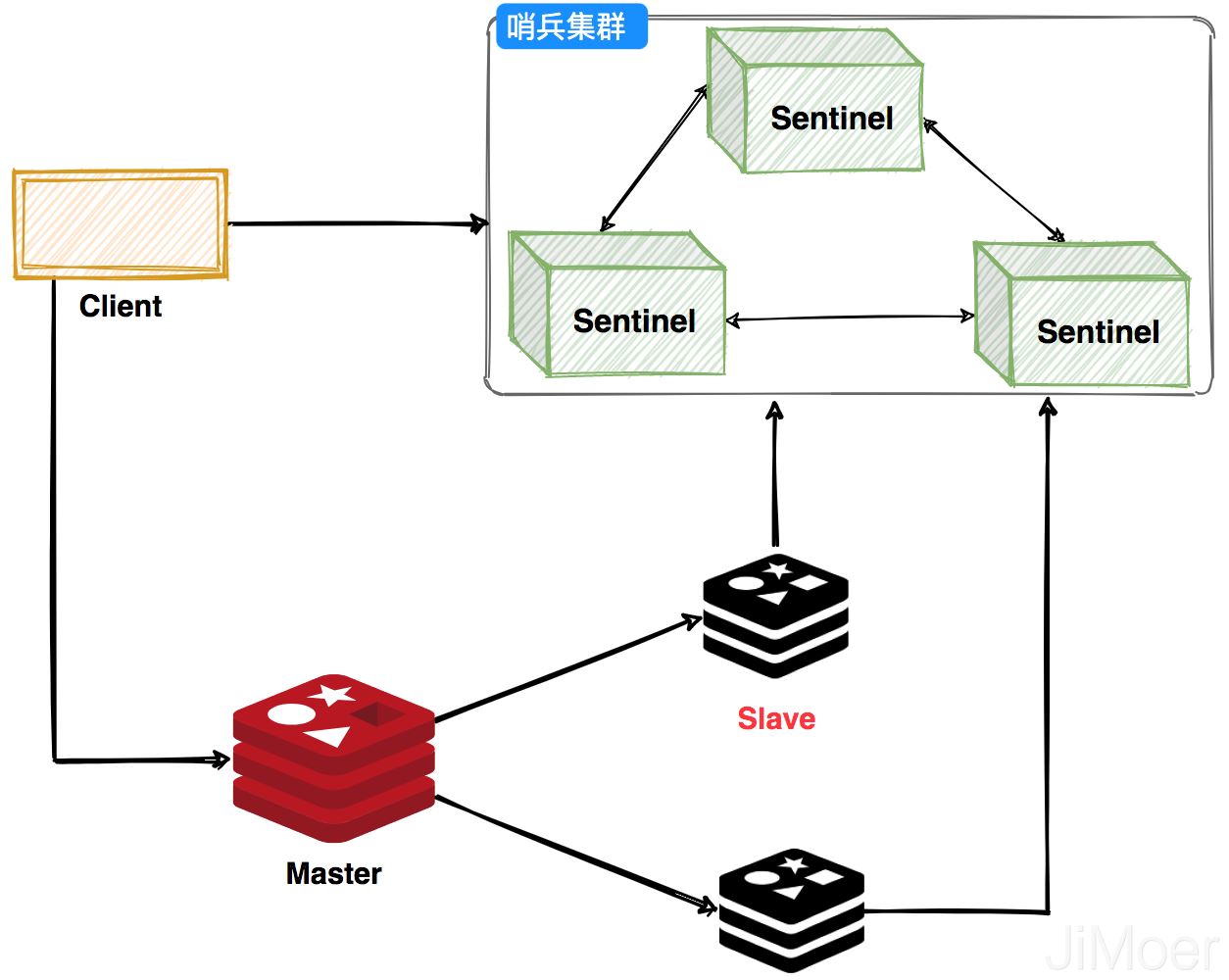
哨兵集群工作过程,主节点挂掉之后会选举出新的主节点,然后监控挂掉的节点,当挂掉的节点恢复后,原先的主节点就会变成从节点,从新的主节点那里建立主从关系。
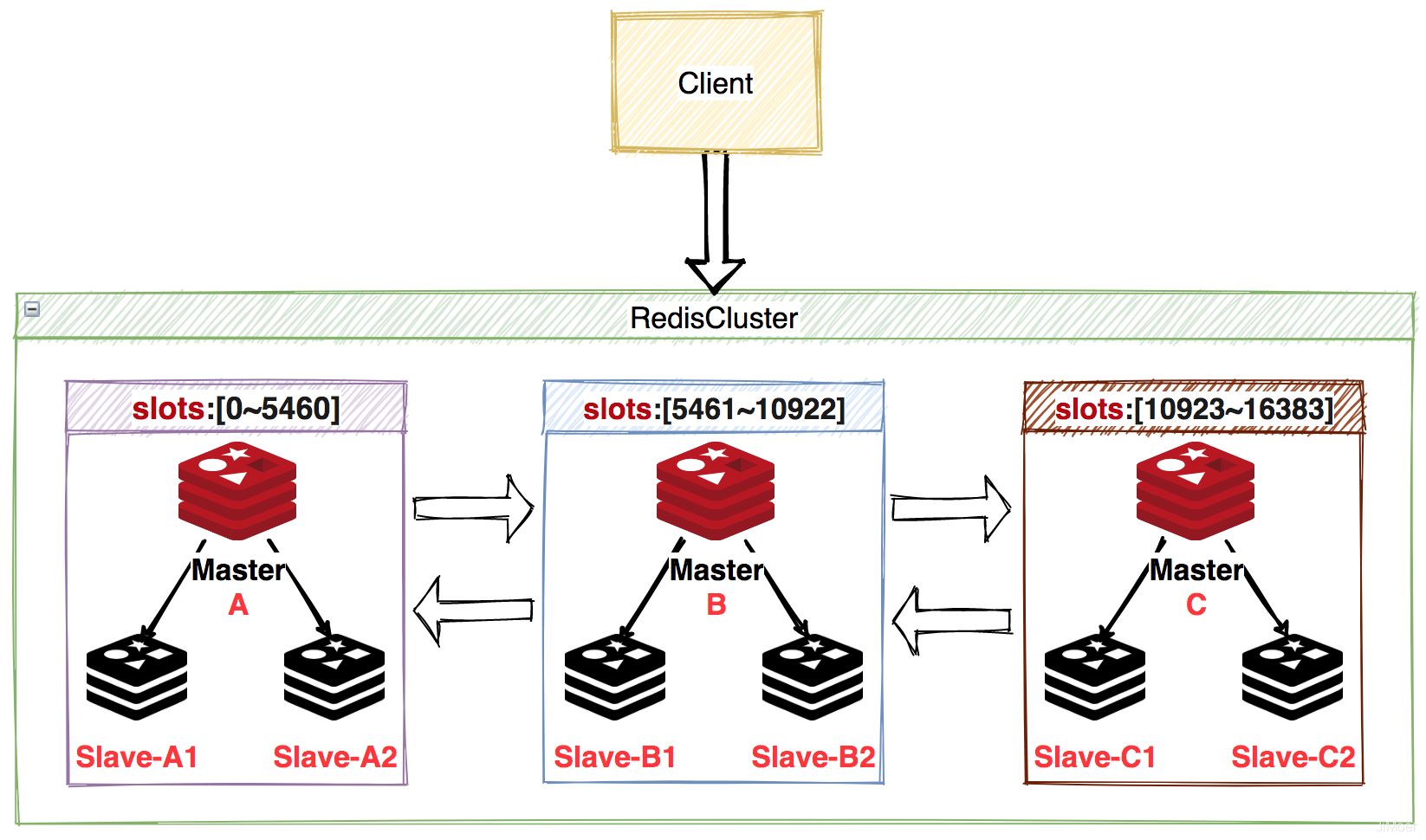
集群分片(Redis Cluster)
Redis Cluster是Redis官方推荐的集群模式,Redis Cluster将所有数据划分到16384个槽(slots)中,每个节点负责一部分槽位的读写操作。
存储
Redis Cluster默认是通过CRC16算法获取到key的hash值,然后再对16384进行取余(CRC16(key)%16384),获取到的槽位在哪个节点负责的范围内(这里一般是会有一个槽位和节点的映射表来进行快速定位节点的,通常使用bitmap来实现),就存储在哪个节点上。
重定向
当Redis Cluster的客户端在和集群建立连接的时候,也会获得一份槽位和节点的配置关系(槽位和节点的映射表),这样当客户端要查找某个key时,可以直接定位到目标节点。




