介绍
这篇文章将为大家详细讲解有关使用Python爬虫怎么登陆到哔哩哔哩,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
? ?首先利用xpath或者css选择器等方法找到要输入内容的元素位置,然后用自动化爬虫工具硒模拟点击输入等操作来进行登录并分析页面,获取点选验证码的点选图片,通过将图片发送给快识别打码平台识别后获取坐标信息,根据快识别返回的数据,模拟坐标的点选,即可实现登录。
前期准备
1。下载chrome司机
? ?就是下载谷歌浏览器的驱动器,当然如果你用其他浏览器那么就要下载其他浏览器的相应驱动,这里我以铬浏览器为例,为什么要用英文呢?啊,这还用问当然是为了洋气啦!(手动狗头)
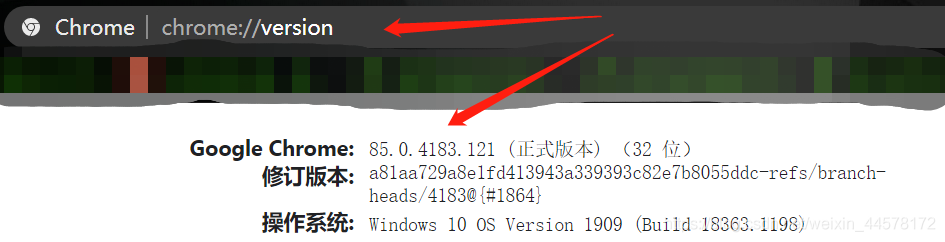
? ?下载驱动的时候必须要下载相应的版本,可以在浏览器上方输入<代码> chrome://版本>
 #快识别网址,http://www.kuaishibie.cn/#界面
import base64
import json
import 请求
def base64_api (uname pwd, img):
,& # 39;& # 39;& # 39;
,验证码识别接口
,:param uname:快识别用户名
,:param pwd:快识别密码
,:param img:图片路径
:返回:大敌;返回识别结果
,& # 39;& # 39;& # 39;
,with 开放(img, & # 39; rb # 39;), as f:=,,base64_data base64.b64encode (f.read ())=,,b64 base64_data.decode ()
,data =, {“username": uname,,“password":, pwd,,“image":, b64,“typeid": 21}
,# result =, json.loads (requests.post (“http://api.ttshitu.com/base64", json=数据)。text)=,,result json.loads (requests.post (“http://api.ttshitu.com/imageXYPlus", json=数据)。text)
结果,if [& # 39;成功# 39;):
结果,return [“data"] [“result"]
,其他的:
,return 结果(“message")
#快识别网址,http://www.kuaishibie.cn/#界面
import base64
import json
import 请求
def base64_api (uname pwd, img):
,& # 39;& # 39;& # 39;
,验证码识别接口
,:param uname:快识别用户名
,:param pwd:快识别密码
,:param img:图片路径
:返回:大敌;返回识别结果
,& # 39;& # 39;& # 39;
,with 开放(img, & # 39; rb # 39;), as f:=,,base64_data base64.b64encode (f.read ())=,,b64 base64_data.decode ()
,data =, {“username": uname,,“password":, pwd,,“image":, b64,“typeid": 21}
,# result =, json.loads (requests.post (“http://api.ttshitu.com/base64", json=数据)。text)=,,result json.loads (requests.post (“http://api.ttshitu.com/imageXYPlus", json=数据)。text)
结果,if [& # 39;成功# 39;):
结果,return [“data"] [“result"]
,其他的:
,return 结果(“message")
三,完整代码
? ?代码中的一些难点和相关步骤我都做了注释,根据上面给出的编程思路大家一步一步做就好了,我就不再详细解释了,如果任何问题欢迎评论区提问或者私信我都可以喔~
# login_bilibili
得到selenium import webdriver
import 时间
得到PIL import 形象
得到selenium.webdriver import ActionChains #导入动作链模块
时间=KUAI_USERNAME & # 39;快识别账号& # 39;
时间=KUAI_PASSWORD & # 39;快识别密码& # 39;
时间=USERNAME & # 39; B站账号& # 39;
时间=PASSWORD & # 39; B站密码& # 39;
#创建浏览器对象
时间=driver webdriver.Chrome (executable_path=& # 39; chromedriver.exe& # 39;)
#打开请求网页页面
driver.get (& # 39; https://passport.bilibili.com/login& # 39;)
driver.implicitly_wait(10), #隐式等待浏览器渲染完成,睡眠是强制等待
# driver.execute_script (“document.body.style.zoom=& # 39; 0.67 & # 39;“), #浏览器内容缩放67%
driver.maximize_window() #最大化浏览器
& # 39;& # 39;& # 39;
用硒自动化工具操作浏览器,操作的顺序和平常用浏览器操作的顺序是一样的
& # 39;& # 39;& # 39;
& # 39;& # 39;& # 39;
找到用户名和密码框输入密码
& # 39;& # 39;& # 39;
时间=user_input driver.find_element_by_xpath (& # 39;//* [@ id=發ogin-username"] & # 39;), #使用xpath定位用户名标签元素
user_input.send_keys(用户名)
time . sleep (1)
时间=user_input driver.find_element_by_xpath (& # 39;//* [@ id=發ogin-passwd"] & # 39;), #用户密码标签
user_input.send_keys(密码)
time . sleep (1)
#点击登录
时间=Login_input driver.find_element_by_css_selector (& # 39; # geetest-wrap 祝辞,div 祝辞,div.btn-box 祝辞,a.btn.btn-login& # 39;)
Login_input.click ()
time . sleep (5)
#对图片验证码进行提取
时间=img_label driver.find_element_by_css_selector (& # 39; body 祝辞,div.geetest_panel.geetest_wind 祝辞,div.geetest_panel_box.geetest_no_logo.geetest_panelshowclick 祝辞,div.geetest_panel_next 祝辞,div 祝辞,div # 39;), #提取图片标签
#保存图片
driver.save_screenshot (& # 39; big.png& # 39;), #截取当前整个页面
time . sleep (5)
#位置可以获取这个元素左上角坐标
打印(img_label.location)
#大小可以获取这个元素的宽(宽度)和高(高度)
打印(img_label.size)
#计算验证码的左右上下横切面
时间=left img_label.location [& # 39; x # 39;】
时间=top img_label.location [& # 39; y # 39;】
时间=right img_label.location [& # 39; x # 39;], +, img_label.size[& # 39;宽度# 39;】
时间=down img_label.location [& # 39; y # 39;], +, img_label.size[& # 39;高度# 39;】
我=,Image.open (& # 39; big.png& # 39;)
我=,im.crop((左,上,右,下)
im.save (& # 39; yzm.png& # 39;)
#对接打码平台
得到interface import base64_api #显示报错也无妨,可以运行的不要被唬住
时间=img_path & # 39; yzm.png& # 39;
时间=result base64_api (uname=KUAI_USERNAME, pwd=KUAI_PASSWORD, img=img_path)
打印(结果)
打印(& # 39;验证码识别结果:& # 39;,,结果)
时间=result_list result.split (& # 39; | & # 39;)
for result result_list拷贝:=,,x result.split (& # 39; & # 39;) [0]=,,y result.split (& # 39; & # 39;) [1]
(司机),ActionChains .move_to_element_with_offset (img_label, int (x), int (y)) .click () .perform(), #,执行()执行整个动作链
#点击确认按钮
null
null
null
null





