
介绍 select *,得到table where column_name =, some_value; <李> import pandas as pd
import numpy as np
时间=df pd.DataFrame({& # 39;一个# 39;:,& # 39;foo bar foo bar foo bar foo foo # 39; .split (),
,,,,,,,,,& # 39;b # 39;:, & # 39; one one two three two two one 3 # 39; .split (),
,,,,,,,,,& # 39;c # 39;:, np.arange (8), & # 39; d # 39;:, np.arange (8), *, 2}) df (df(& # 39;一个# 39;],==,& # 39;foo # 39;], #,判断等式是否成立 mask =, df(& # 39;一个# 39;],==,& # 39;foo # 39;
pos =, np.flatnonzero(面具),#,返回的是数组([0,,2,4,6,7])
df.iloc (pos)
#常见的iloc用法
df。iloc (: 3, 1:3) df.set_index(& # 39;一个# 39;,,附加=True,,删除=False)方式(& # 39;foo # 39;,,水平=1),#,xs方法适用于多重索引DataFrame的数据筛选
#,更直观点的做法
df.index=df[& # 39;一个# 39;],#,将一个列作为DataFrame的行索引
df.loc [& # 39; foo # 39;,,,)
#,使用布尔
df.loc [df[& # 39;一个# 39;]==& # 39;foo # 39;] df.query (& # 39;==癴oo" & # 39;)
#,多条件
df.query (& # 39;==癴oo", |,==癰ar" & # 39;) df.loc (df (& # 39; column_name& # 39;],==, some_value] df.loc (df (& # 39; column_name& # 39;] .isin (some_value)], #, some_value是可迭代对象以前 df.loc [(df (& # 39; column_name& # 39;],祝辞=,A),,, (df (& # 39; column_name& # 39;], & lt;=, B)] df.loc (df (& # 39; column_name& # 39;], !=, & # 39; some_value& # 39;】
df.loc [~ df [& # 39; column_name& # 39;] .isin (& # 39; some_values& # 39;)], # ~取反
利用熊猫怎么对指定列值对应的行进行筛选?相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
在熊猫中怎么样实现类似mysql查找语句的功能:
熊猫中获取数据的有以下几种方法:
布尔索引
<李>位置索引
<李>标签索引
<李>使用API
假设数据如下:

布尔索引
该方法其实就是找出每一行中符合条件的真值(真值),如找出一列中所有值等于foo
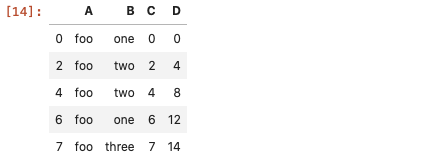
位置索引
使用iloc方法,根据索引的位置来查找数据的。这个例子需要先找出符合条件的行所在位置

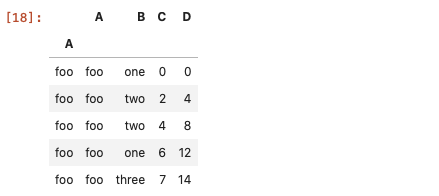
标签索引
如何DataFrame的行列都是有标签的,那么使用loc方法就非常合适了。
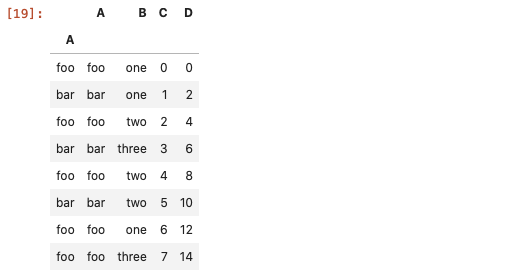
<强>使用API
<代码> pd.DataFrame。查询方法在数据量大的时候,效率比常规的方法更高效。
<强>数据提取不止前面提到的情况,第一个答案就给出了以下几种常见情况:
1,筛选出列值等于标量的行,用==
2,筛选出列值属于某个范围内的行,用isin
3,多种条件限制时使用,,,的优先级高于祝辞=或& lt;=,所以要注意括号的使用
4,筛选出列值不等于某个/些值的行
看完上述内容,你们掌握利用熊猫怎么对指定列值对应的行进行筛选的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注行业资讯频道,感谢各位的阅读!




