
这期内容当中小编将会给大家带来有关布隆过滤器的工作原理是什么,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器的工作原理
假设一个长度为m的bit类型的数组,即数组中每个位置只占一个bit,每个bit只有两种状态:0,1,所有bit的初始状态都为0。
再假设一共有k个哈希函数,这些函数的输出域大于或者等于m,并且这些哈希函数,彼此之间相互独立,每个哈希函数计算出来的结果是独立的,可能相同也可能不相同,对每一个计算出来的结果都对m取余(%m),然后再将数组下标位置置为1。
我们这里假设m为13,k为3的布隆过滤器,来看看布隆过滤器的工作原理:

当我们要映射一个值到布隆过滤器时,首先计算三个哈希函数的值,然后对13取余,映射到对应位中,图中映射到2,6,10,这样我们就完成了一个值的映射。
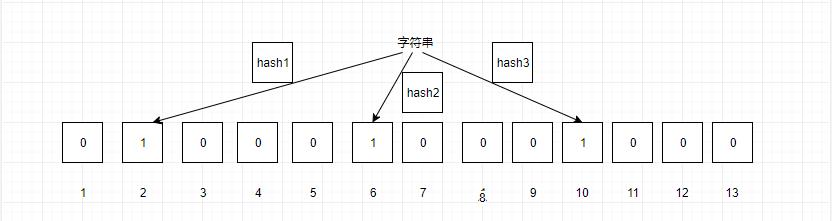
那么怎么判断一个值是否存在,当一个值输入时,通过三个哈希函数,然后取余,我们就可以得到对应的三个位置,我们只需要判断这三个位置是否都为1,如果都为1,则该值存储,反之不存在。
但是有一个特殊情况,前面说了不同的哈希函数可能计算可能相同也可能不相同,而且不同的哈希函数对不同的值计算出来的值可能一样,这就造成一个结果,一个值通过哈希和取余得到的位置,早就被其它值给置1了,当我们存储的值过多,而这个bit数组过小,都会造成这种情况更多的发生,一个值明明不存在,而它的所有位置早就被其它不同值置1,造成了误判,这里就对布隆过滤器提出了一个指标:失误率p。
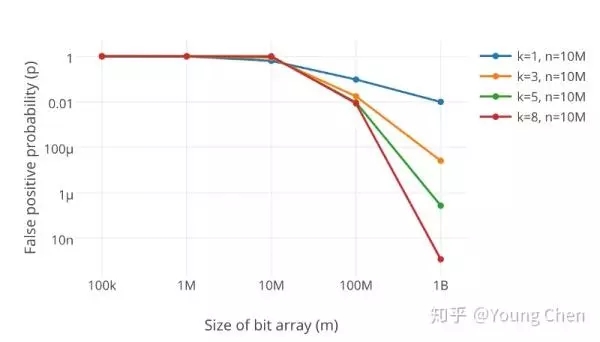
在同样数据规模下,不同大小的bit数组及不同数量k的哈希函数对误判率的结果:
如何选取最合适的m(bit数组的大小)及k(哈希函数的数量),在已知n(需要映射的值得数量)及失误率p的情况下:
m的选取:
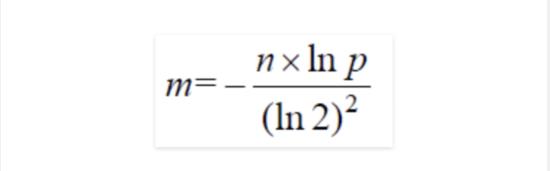
k的选取:

给个例子:假设n=100亿,p=0.01%
通过公式计算出来m=19.19n,向上取整位20n,即2000亿个bit,也就是25gb。
通过公式计算出来k=14。
计算真实失误率:

根据公式计算出来的真实失误率位0.006%。
c语言实现
#include# define Size 100年 # define BitSIZE Size *, 4, *, 8//c语言中一个整型数据类型4个字节, int 钻头(大小)={0}; ,, int SDBMHash (char * str) { unsigned 才能int hash =, 0; while 才能;(str) {才能 ,,,//,equivalent :, hash =, 65599 * hash , +, * str (+ +); ,,,hash =, (* str + +), +, (hash & lt; & lt;, 6), +, (hash & lt; & lt;, 16),背后,散列; ,,} return 才能;(hash ,, 0 x7fffffff); } int RSHash (char * str) { unsigned 才能int b =, 378551; unsigned 才能int a =, 63689; unsigned 才能int hash =, 0; , while 才能;(str) {才能 ,,,hash =, hash *, a , +, * str (+ +); ,,,a *=, b; ,,} , return 才能;(hash ,, 0 x7fffffff); } int JSHash (char * str) { unsigned 才能int hash =, 1315423911; , while 才能;(str) {才能 ,,,hash ^=, ((hash & lt; & lt;, 5), +, * str (+ +), +, (hash 在祝辞,2)); ,,} , return 才能;(hash ,, 0 x7fffffff); } void 插入(int 哈希){ ,,//才能int value =,哈希% BitSIZE;,((0 - 3200)范围的值)//才能int listindex =, value /, 32岁,,(listindex为数组下标)//才能int bitindex =, value %, 32岁,,(某位) ,, int 才能;value =,哈希% BitSIZE; int 才能;listindex =, value /, 32; int 才能;bitindex =, value %, 32; int 才能;temp =,钻头(listindex); 位才能[listindex],=,一点(listindex),,, (1, & lt; & lt;, bitindex); 位才能[listindex],=,一点[listindex], |,温度; } int Serach (int 哈希){ int 才能;value =,哈希% BitSIZE; int 才能;listindex =, value /, 32; int 才能;bitindex =, value %, 32; if 才能;(一些[listindex], |, (1, & lt; & lt;, bitindex)) { ,,,return 1; ,,} return 才能;0; } int main (), { ,, char 才能str1 [],=,“abc123"; ,,//才能在布隆过滤器中插入某值 插入才能(SDBMHash (str1)); 插入才能(RSHash (str1)); 插入才能(JSHash (str1)); ,,//才能在布隆过滤器中判断某值是否存在 int 才能;小姐:=,0; 小姐:才能=,我+ Serach (SDBMHash (str1)); 小姐:才能=,我+ Serach (RSHash (str1)); 小姐:才能=,我+ Serach (JSHash (str1)); 如果才能(小姐:==,3){ ,,,printf(“字符串:% s存在\ n", str1); ,,} return 才能;0; null 布隆过滤器的工作原理是什么




