
怎么样搭建Hadoop3.2.0集群?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
<强>一端口变化
3.2.0版本中namenode页面端口是9870年,datanode管理端口是8088年,所以需要开放这两个端口还给web页面访问
<强>二但没有YARN_RESOURCEMANAGER_USER定义。流产手术
hadoop-env。sh中不光需要配置java主目录,还需要声明下面这些用户变量,不然无法启动:
export JAVA_HOME=/usr/地方/jdk/jdk1.8.0_191
出口HDFS_NAMENODE_USER=出口HDFS_DATANODE_USER根
=
根出口HDFS_SECONDARYNAMENODE_USER=出口YARN_RESOURCEMANAGER_USER根
=
根出口YARN_NODEMANAGER_USER=根<强>三3.2.0版本mapred-site。xml文件配置需要加mapreduce.application.classpath属性
& lt; property>& lt; name> mapreduce.application.classpath& lt; value>/usr/local/hadoop3/etc/hadoop,/usr/local/hadoop3/share/hadoop/common/*,/usr/local/hadoop3/share/hadoop/common/lib/*,/usr/local/hadoop3/share/hadoop/hdfs/*,/usr/local/hadoop3/share/hadoop/hdfs/lib/*,/usr/local/hadoop3/share/hadoop/mapreduce/*,/usr/local/hadoop3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop3/share/hadoop/yarn/*,/usr/local/hadoop3/share/hadoop/yarn/lib/* & lt;/value>& lt;/property>
<强>四salave文件编程工人文件了,内容配置是一样的
<强>五启动成功不报的错,但最蛋疼的生活节点为0问题
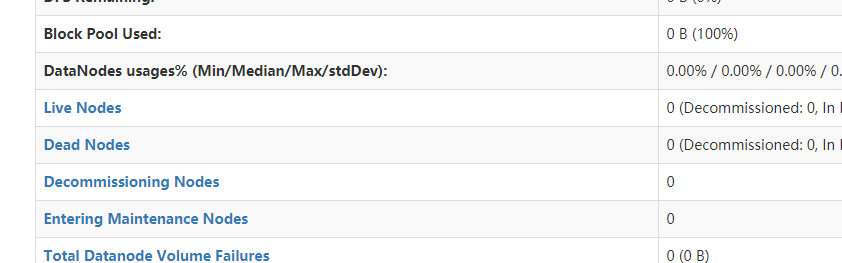
解决步骤:
一先查看datanode日志:
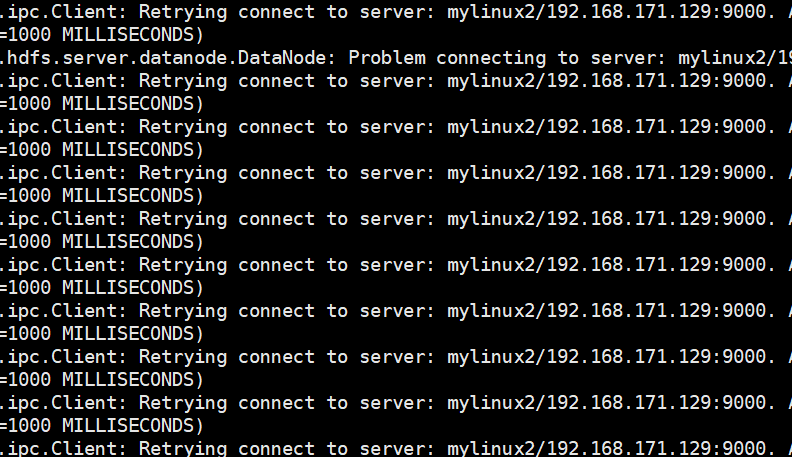
如果出现这个说明连接配置有问题,查看核心位点。xml配置,这个是配置datanode和namnode通信的:
一看
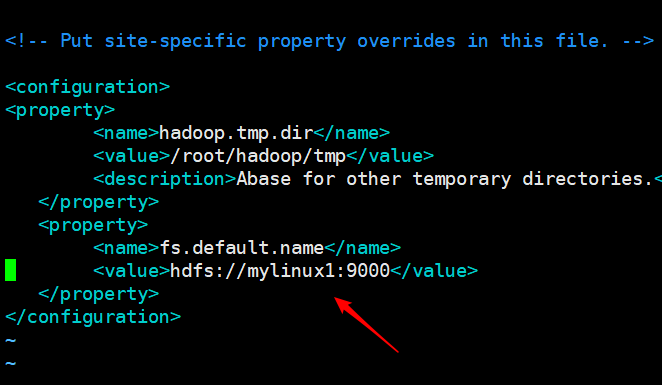
这里配置的连接地址有问题
hdfs应该配置成namnode的地址,不能配置成datanode的地址,所有节点都一样,这个地址,配置完成重启成功
网上还有说/etc/热点解析不成功的,这个也是一个原因,配置好域名映射就可以了,重要的是先看日志分析是什么问题
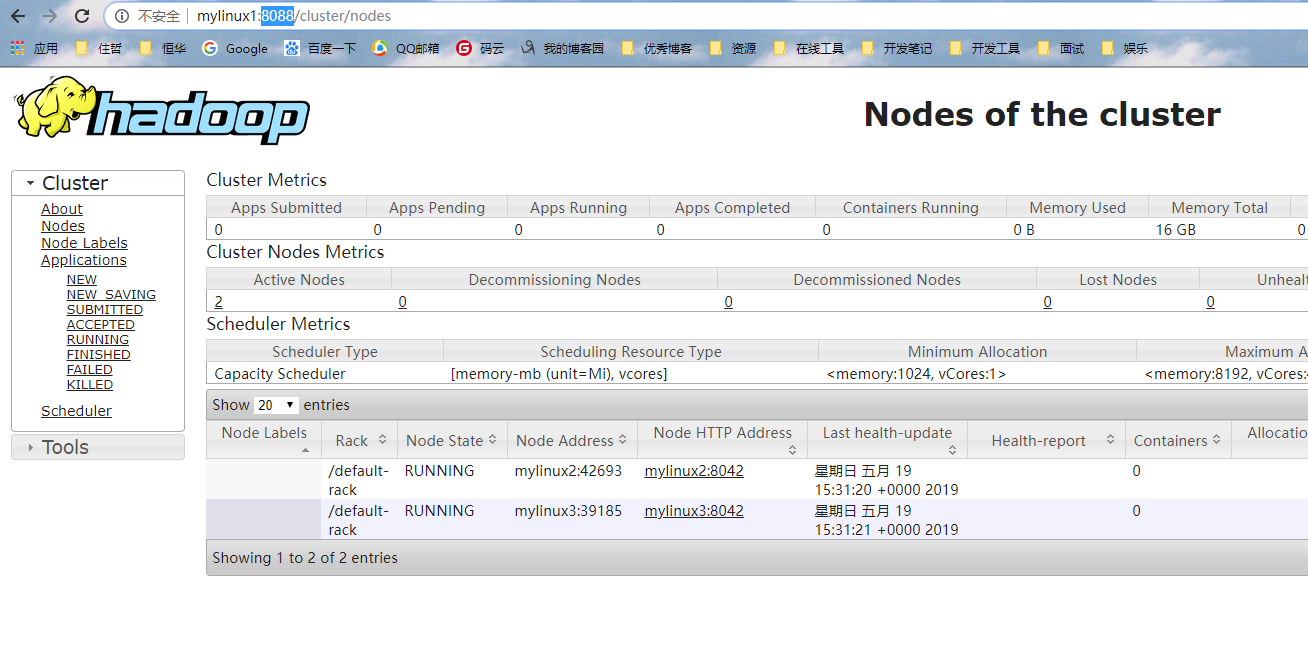
最后成功页面

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注行业资讯频道,感谢您对的支持。
怎么样搭建Hadoop3.2.0集群




