
介绍
利用Java如何实现读取文章中重复的中文?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
<强>以下是代码和运行效果:
<强>实现方法:
进口. io . *;
进口java.util。*;/* *
*由chunmiao>进口java.io.IOException;
进口java.util.HashSet;
公开课主要{
公共静态void main (String [] args)抛出IOException {
字符串文件名=皌est.txt";
HashSet结果=new HashSet ();
ReadArticle阅读=new ReadArticle(文件名,结果);
read.createData ();
System.out.println(“这篇文章中的重复出现的词或句子有以下几个词或句子:\ n");
(字符串s:结果){
System.out.println(年代);
}
}
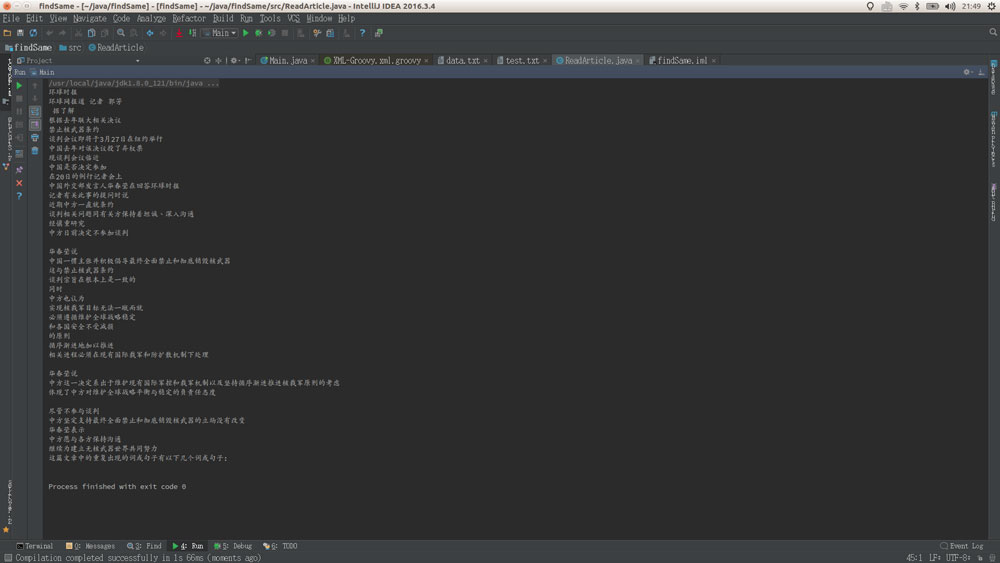
} <>强读取的文章内容:
<强>正则匹配结果(去掉多余字符):
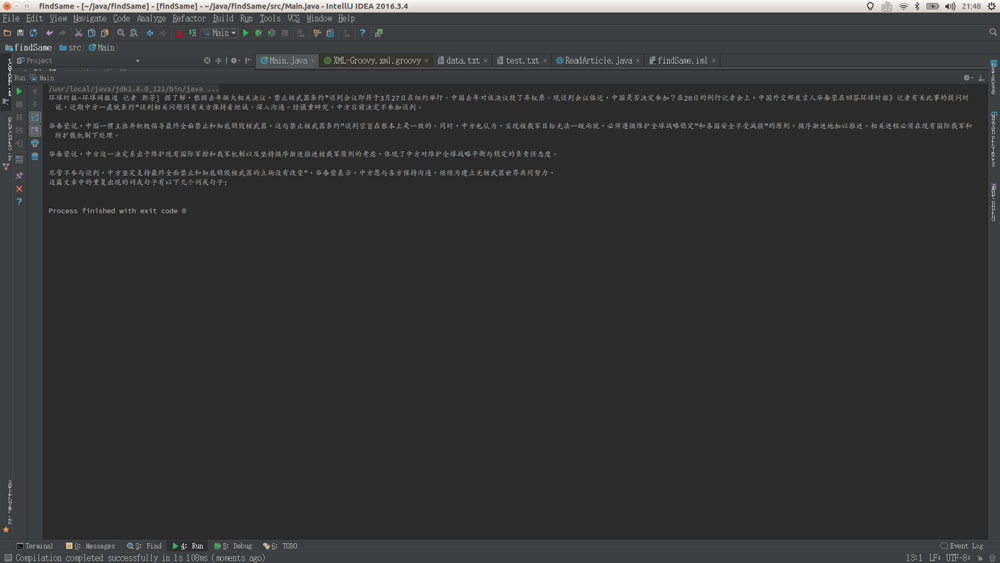
<强>字符串转换成ArrayList:
<强>最终处理结果:

<强>其实从上面的结果可以看出。单纯的操控字符串并不能判断它是否是一个完整的词和句,应该还要配合数据库字典来匹配上面的结果,从而找出真正的词和句
关于利用Java如何实现读取文章中重复的中文问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注行业资讯频道了解更多相关知识。




