
介绍 & # 39; & # 39; & # 39;选择文件功能& # 39;& # 39;& # 39;
def selectPath ():
#选择文件path_接收文件地址
path_=tkinter.filedialog.askopenfilename ()
#通过取代函数替换绝对文件地址中的/来使文件可被程序读取
#注意:\ \转义后为\,所以\ \ \ \转义后为\ \
path_=path_.replace (“/?“\ \ \ \“)
#道路设置path_的值
path.set (path_)
返回路径
#得到的DataFrame读入所有数据
data=https://www.yisu.com/zixun/pd.read_excel(文件名,头=0,usecols=癆, B, C, D, E, F, G, H,我”)
# DataFrame转化为数组
DataArray=data.values
#读取已使用年限作为标签
Y=DataArray (: 8)
#读取其他参数作为自变量,影响因素
X=DataArray [: 0:8]
#字符串转变为整数
因为我在范围(len (Y)):
[我]=int (Y[我]。替换("年"," "))
X=np.array (X) #转化为数组
Y=np.array (Y) #转化为数组
根=Tk ()
root.geometry (+ 500 + 260)
#背景图设置
帆布=tk。画布(根、宽度=600,身高=200,bd=0, highlightthickness=0)
imgpath=' 1. jpg '
img=Image.open (imgpath)
照片=ImageTk.PhotoImage (img)
#背景图大小设置
画布。create_image(700、400、图像=图)
canvas.pack ()
路径=StringVar ()
#标签名称位置
label1=tk。标签(文本="目标路径:”)
label1.pack ()
e1=tk。条目(textvariable=路径)
e1.pack ()
bn1=tk。按钮(文本="路径选择”,命令=selectPath)
bn1.pack ()
bn2=tk。按钮(文本="模型训练”,命令=火车)
bn2.pack ()
bn3=tk。”按钮(文本="模型预测,命令=测试)
bn3.pack ()
#标签按钮等放在背景图上
画布。create_window(50 50宽度=150,身高=30,
窗口=label1)
画布。create_window(280年,50岁的宽度=300,身高=30,
窗口=e1)
画布。create_window(510年,50岁的宽度=150,身高=30,
窗口=bn1)
画布。create_window(100,宽度=150,身高=30,
窗口=bn2)
画布。create_window(510、100、宽度=150,高度=30,
窗口=bn3)
root.mainloop ()
这篇文章运用简单易懂的例子给大家介绍利用Python编写一个数据预测工具,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
大数据预测是大数据最核心的应用,是它将传统意义的预测拓展到“现测”。大数据预测的优势体现在,它把一个非常困难的预测问题,转化为一个相对简单的描述问题,而这是传统小数据集根本无法企及的。从预测的角度看,大数据预测所得出的结果不仅仅是用于处理现实业务的简单,客观的结论,更是能用于帮助企业经营的决策。
在过去,人们的决策主要是依赖20%的结构化数据,而大数据预测则可以利用另外80%的非结构化数据来做决策。大数据预测具有更多的数据维度,更快的数据频度和更广的数据宽度。与小数据时代相比,大数据预测的思维具有3大改变:实样而非抽样;预测效率而非精确;相关关系而非因果关系。
而今天我们就将利用Python制作可视化的大数据预测部分集成工具,其中数据在这里使用一个实验中的数据。普遍性的应用则直接从文件读取即可。其中的效果图如下:

<强>实验前的准备
首先我们使用的Python版本是3.6.5所用到的模块如下:
- <李> sklearn模块用来创建整个模型训练和保存调用以及算法的搭建框架等等。 <李> numpy模块用来处理数据矩阵运算。 <李> matplotlib模块用来可视化拟合模型效果。 <李>枕头库用来加载图片至GUI界面。 <李>熊猫模块用来读取csv数据文件。 <李> Tkinter用来创建GUI窗口程序。
李,
<强>数据的训练和训练的GUI窗口
经过算法比较,发现这里我们选择使用sklearn简单的多元回归进行拟合数据可以达到比较好的效果。
(1)首先是是数据的读取,通过设定选定文件夹函数来读取文件,加载数据的效果:
效果如下可见:
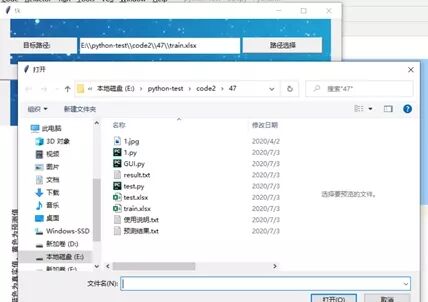
(2)然后是数据的拟合和可视化模型效果:
#模型拟合 reg=LinearRegression () reg。fit (X, Y) #预测效果 预测=reg.predict (np.array ([X [0]])) Y_predict=reg.predict (X) 打印(Y_predict) #横坐标 x_label=[] 因为我在范围(len (Y)): x_label.append(我) #绘图 无花果,ax=plt.subplots () #真实值分布散点图 plt。散射(x_label, Y) #预测值分布散点图 plt。散射(x_label Y_predict) #预测值拟合直线图 plt。情节(x_label Y_predict) #横纵坐标 ax.set_xlabel(& # 39;预测值与真实值模型拟合效果图& # 39;) ax.set_ylabel(& # 39;蓝色为真实值,黄色为预测值& # 39;) #将绘制的图形显示到tkinter:创建属于根的帆布画布,并将图f置于画布上 帆布=FigureCanvasTkAgg(无花果,主人=根) canvas.draw() #注意展示方法已经过时了,这里改用画画 .pack canvas.get_tk_widget () () # matplotlib的导航工具栏显示上来(默认是不会显示它的) 工具栏=NavigationToolbar2Tk(画布,根) toolbar.update () canvas._tkcanvas.pack () #弹窗显示 messagebox.showinfo (title=& # 39;模型情况& # 39;,消息=澳P脱盗吠瓿?“) 其中的效果如下可见:利用Python编写一个数据预测工具




