
javascrip中缓存的工作原理是什么?这个问题可能是我们日常学习或工作经常见到的。希望通过这个问题能让你收获颇深。下面是小编给大家带来的参考内容,让我们一起来看看吧!
前言
缓存是指:为了降低服务器端的访问频率,减少通信数量,前端将获取的数据信息保存下来,当再次需要时,就使用所保存的数据。
缓存对用户体验和通信成本都会造成很大的影响,所以要尽可能地去灵活使用缓存机制。
缓存的工作原理
HTTP缓存是一个以时间为维度的缓存。
浏览器在第一次请求中缓存了响应,而后续的请求可以从缓存提取第一次请求的响应。从而达到:减少时延而且还能降低带宽消耗,因为可能压根就没有发出请求,所以网络的吞吐量也下降了。
工作原理
浏览器发出第一次请求,服务器返回响应。如果得到响应中有信息告诉浏览器可以缓存此响应。那么浏览器就把这个响应缓存到浏览器缓存中。
如果后续再发出请求时,浏览器会先判断缓存是否过期。如果没有过期,浏览器压根就不会向服务器发出请求,而是直接从缓存中提取结果。
比如:访问掘金站点
从Size中可以看出,disk cache是从硬盘中提取的缓存信息。
缓存过期了
如果缓存过期了,也并不一定向第一个请求那样服务器直接返回响应。
浏览器的缓存时间过过期了,就把该请求带上缓存的标签发送给服务器。这时如果服务器觉得这份缓存还能用,那就返回304响应码。浏览器将继续使用这份缓存。
比如:选择上面图中的其中一份缓存文件,copy请求url在curl中展示
首先加-I获取原始请求,查看etag或last-modified头部。
因为浏览器缓存过期之后,请求就会带上这些头部一起发送给服务器,让服务器判断是否还能用。
针对etag头部,加一个if-none-match头部带上etag的值询问服务器。当然也可以针对last-modified头部,加一个if-modified-since头部询问。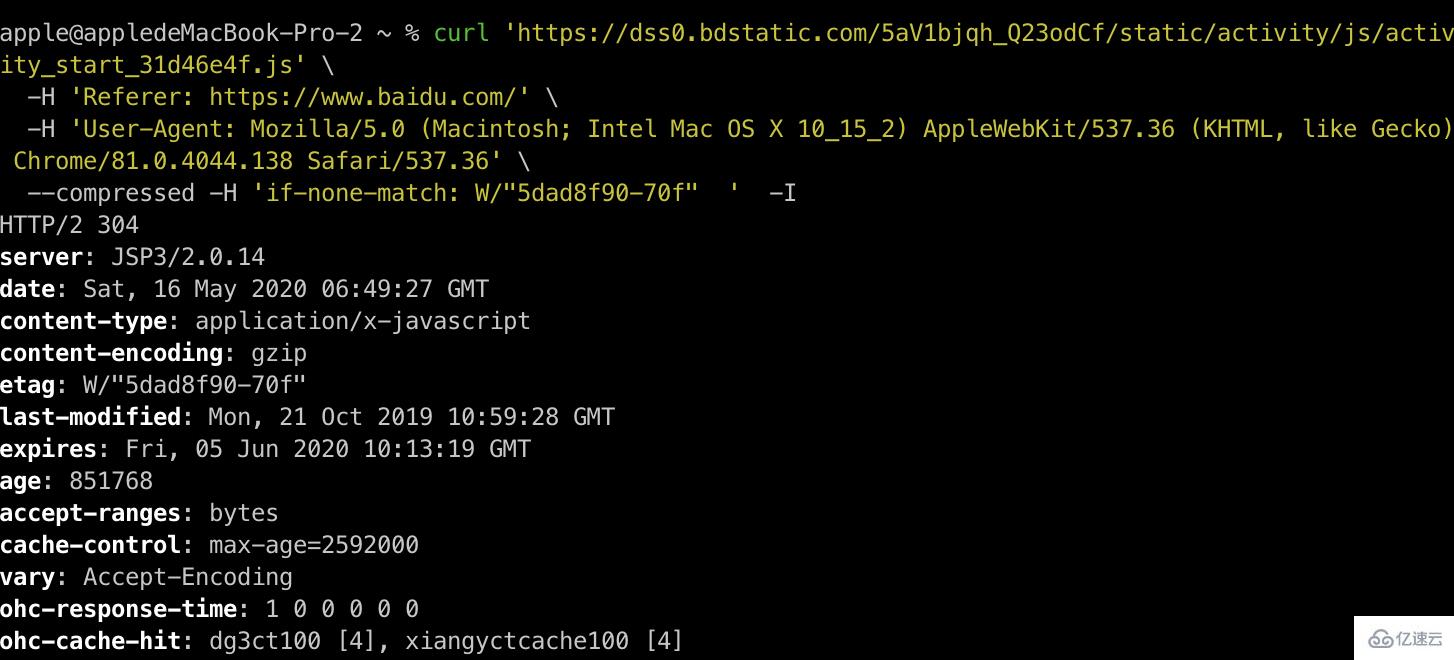
返回的是304。304的好处就是不携带包体,也就是说content-length为0,这样就节省了大量的带宽。
共享缓存
浏览器缓存是私有缓存,只提供给一个用户使用的。
而共享缓存是放在服务器上的,可以提供多个用户使用。比如说某个比较热点的视频等热点资源就会放在代理代理服务器的缓存中,以减低源服务器的压力,提升网络效率。
怎么分辨这个资源是代理服务器的缓存还是源服务器发送的呢?
仍然使用掘金的例子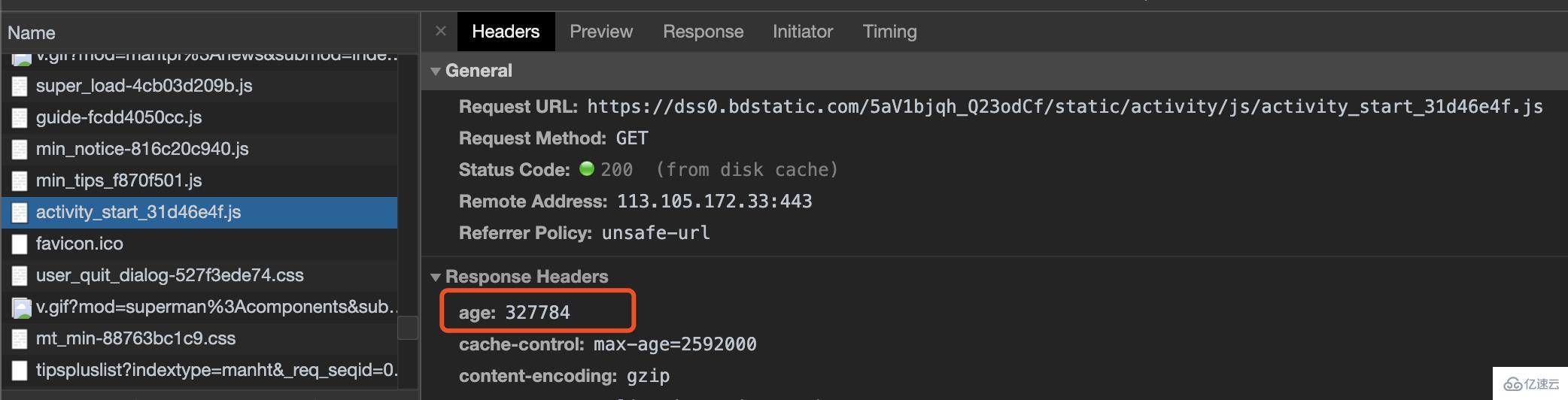
从图中看出这个请求的Response Headers中的age头部,单位是秒。
说明这个缓存是共享缓存返回的,age说明了它在共享缓存存在的时间,图中是327784,也就是在共享缓存中存在了327784秒。
共享缓存也有过期的时候,下面看看共享缓存的工作原理。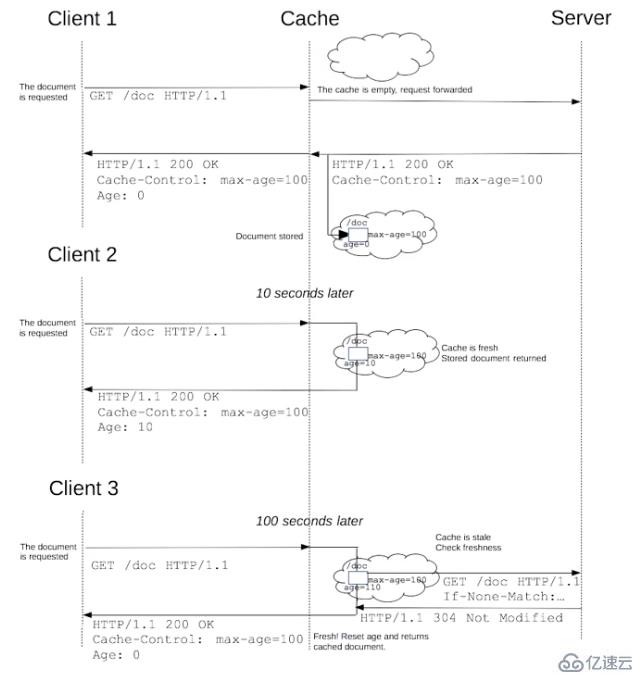
如图所示:
1、当client1发起请求时,Cache也就是代理服务器(共享缓存),转发这条请求给源服务器。源服务器返回响应,并在Cache-Control头部中设定可以缓存100秒。接着在Cache中就会开启一个定时器Age,将响应带上Age:0头部返回给client1。
2、过了10秒后,client2发送相同的请求,Cache中的缓存还没有过期,就带上Age:10头部返回缓存中的响应给client2。
3、过了100秒后,client3发送同样的请求,这时Cache中的缓存已经过期了,就像前面说到那样用条件请求头部If-None-Match带上缓存的指纹发给源服务器。当源服务认为此缓存还能用,就返回304状态码给




