今天看到了mlxtend的包,看了下例子集成得非常简洁。还有一个吸引我的地方是自带了一些数据直接可以用,省去了自己造数据或者找数据的处理过程,所以决定安装体验一下。
首先,sudo pip安装mlxtend得到基础环境。
然后开始看看系统依赖问题的解决。大致看了下基本都是python科学计算用的那几个经典的包,主要是numpy, scipy, matplotlib, sklearn这些。
LINUX环境下的话,一般这些都比较好装皮普一般都能搞的定。
这里要说的一点是matplotlib的话,pip装的时候提示我的几个问题是png和一个叫Freetype的包被需要,但是装的时候又出现问题,所以matplotlib最后选择用
sudo apt-get安装python-matplotlib
直接解决依赖问题。
同样的情况对于scipy也是一样,用
sudo apt-get安装python-scipy
解决。
<强>示例代码
进口numpy np
进口matplotlib。pyplot作为plt
进口matplotlib。gridspec作为gridspec
出现进口itertools
从sklearn。linear_model进口LogisticRegression
从sklearn。支持向量机进口SVC
从sklearn。整体进口RandomForestClassifier
从mlxtend。分类器进口EnsembleVoteClassifier
从mlxtend。数据导入iris_data
从mlxtend。评估导入plot_decision_regions
#初始化分类器
clf1=LogisticRegression (random_state=0)
clf2=RandomForestClassifier (random_state=0)
clf3=SVC (random_state=0,概率=True)
eclf=EnsembleVoteClassifier (clfs=[clf1、clf2 clf3],权重=(2,1,1),投票='软')
#加载一些示例数据
X, y=iris_data ()
X=X (:, (0, 2))
#策划决定区域
gs=gridspec。GridSpec (2, 2)
无花果=plt。8)图(figsize=(10日)
clf,实验室,研磨zip ([clf1、clf2 clf3, eclf),
(“回归”,“随机森林”,“朴素贝叶斯“合奏”),
itertools。产品([0,1],重复=2)):
clf。fit (X, y)
ax=plt。次要情节(gs[研磨[0],研磨[1]])
无花果=plot_decision_regions (X=X, y=y, clf=clf传奇=2)
plt.title(实验室)
plt.show ()
之后就可以来跑一下这个示例代码。
matplot结果如图:
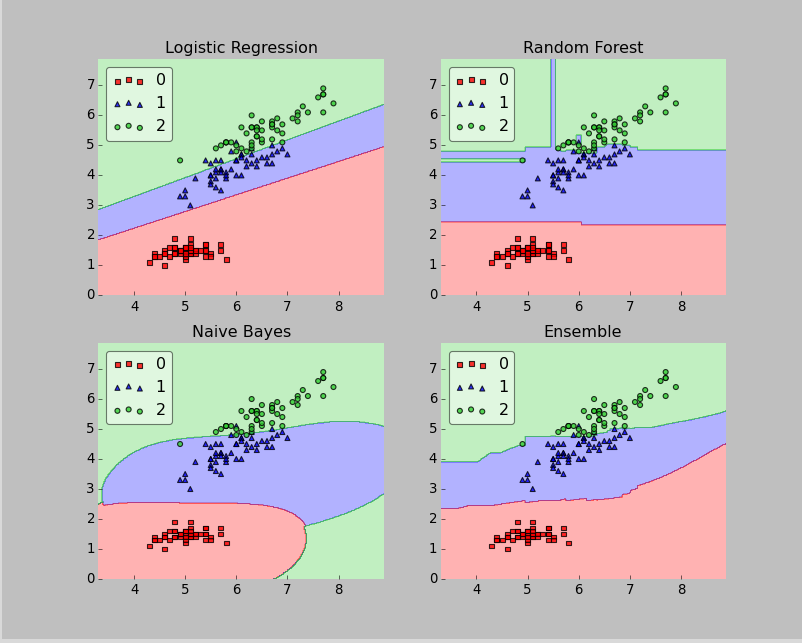
之后就可以开始玩了~ !
附:linux下python科学计算的经典的包的一个总和的命令:
sudo apt-get安装python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。





