
介绍
小编给大家分享一下万亿级数据应该迁移的方法,希望大家阅读完这篇文章后大所收获、下面让我们一起去探讨吧!
背景
在星爷的《大话西游》中有一句非常出名的台词:“曾经有一份真挚的感情摆在我的面前我没有珍惜,等我失去的时候才追悔莫及,人间最痛苦的事莫过于此,如果上天能给我一次再来一次的机会,我会对哪个女孩说三个字:我爱你,如果非要在这份爱上加一个期限,我希望是一万年!”在我们开发人员的眼中,这个感情就和我们数据库中的数据一样,我们多希望他一万年都不改变,但是往往事与愿违,随着公司的不断发展,业务的不断变更,我们对数据的要求也在不断的变化,大概有下面的几种情况:
- <李> <强>分库分表:业务发展越来越快,导致单机数据库承受的压力越来越大,数据量也越来越多,这个时候通常会使用分库的方法去解决这个问题,将数据库的流量均分到不同的机器上。从单机数据库到分库这个过程,我们就需要完整的迁移我们的数据,我们才能成功的分库的方式上使用我们的数据。 <李> <强>更换存储介质:上面介绍的分库,一般来说我们迁移完之后,存储介质依然是同样的,比如说之前使用的是单机Mysql,分库之后就变成了多台机器的Mysql,我们的数据库表的字段都没有发生变化,迁移来说相对比较简单。有时候我们分库分表并不能解决所有的问题,如果我们需要很多复杂的查询,这个时候使用Mysql可能就不是一个靠谱的方案,那么我们就需要替换查询的存储介质,比如使用elasticsearch,这种的迁移就会稍微要复杂一些,涉及到不同存储介质的数据转换。 <李> <>强切换新系统:一般公司在高速发展中,一定会出现很多为了速度快然后重复建设的项目,当公司再一定时间段的时候,往往这部分项目会被合并,变成一个平台或者中台,比如我们一些会员系统,电商系统等等。这个时候往往就会面临一个问题,将老的系统中的数据需要迁移到新的系统中,这个时候就更加复杂了,有可能不仅是存储介质有变动,有可能项目语言也不同,从更上层的角度来看,部门有可能也不同,所以这种数据迁移的难度是比较高,风险也更加的大。
在实际业务开发中,我们会根据不同的情况来做出不同的迁移方案,接下来我们来讨论一下到底应该怎么迁移数据。
数据迁移
数据迁移其实不是一蹴而就的,每一次数据迁移都需要一段漫长的时间,有可能是一周,有可能是几个月,通常来说我们迁移数据的过程基本都和下图差不多: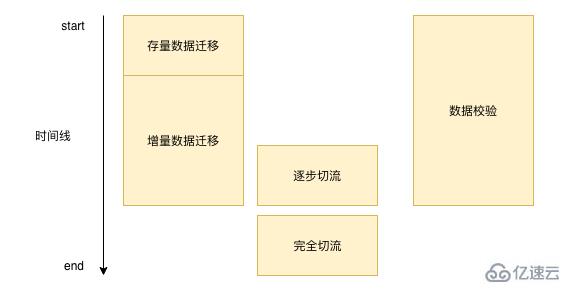 select * from table_name id比;curId id & lt;curId + 10000;复制代码
select * from table_name id比;curId id & lt;curId + 10000;复制代码
3。当id大于等于maxId之后,存量数据迁移任务结束
当然我们在实际的迁移过程中可能不会去使用阿里云,或者说在我们的第三个场景下,我们的数据库字段之间需要做很多转换,DTS不支持,那么我们就可以模仿DTS的做法,通过分段批量读取数据的方式来迁移数据,这里需要注意的是我们批量迁移数据的时候需要控制分段的大小,以及频率,防止影响我们线上的正常运行。




