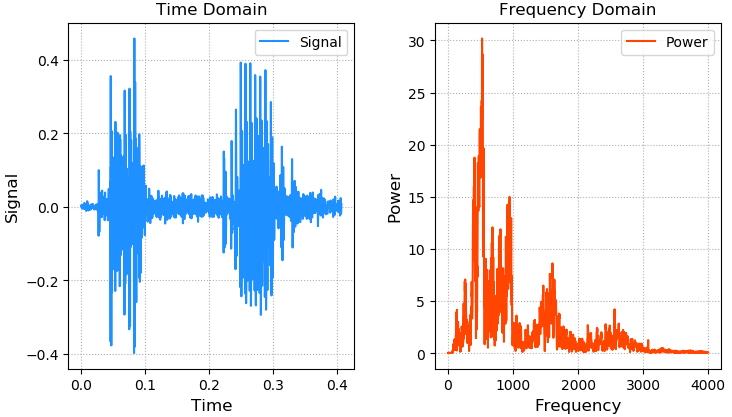
声音的本质是震动,震动的本质是位移关于时间的函数,波形文件(wav)中记录了不同采样时刻的位移。
通过傅里叶变换,可以将时间域的声音函数分解为一系列不同频率的正弦函数的叠加,通过频率谱线的特殊分布,建立音频内容和文本的对应关系,以此作为模型训练的基础。
案例:画出语音信号的波形和频率分布,(freq.wav数据地址)
# - * -编码:utf - 8 - *
进口numpy np
进口numpy。fft是nf
进口scipy.io。wavfile作为wf
进口matplotlib。pyplot作为plt
sample_rate团体=wf.read (“. ./machine_learning_date/freq.wav”)
打印(sample_rate) # 8000采样率
打印(sigs.shape) # (3251)
团体=团体/(2 * * 15)#归一化
*=np.arange (len(团体))/sample_rate
频率=nf.fftfreq(团体。大小,1/sample_rate)
fft算法=nf.fft(团体)
战俘=np.abs (fft算法)
plt.figure(音频)
plt.subplot (121)
plt。标题(时间域)
plt。包含(“时间”,字形大?12)
plt。ylabel(“信号”,字形大?12)
plt.tick_params (labelsize=10)
plt.grid(线型=':')
plt。情节(时间、团体、c=dodgerblue,标签=靶藕拧?
plt.legend ()
plt.subplot (122)
plt。标题(频域)
plt。包含(“频率”,字形大?12)
plt。ylabel(“权力”,字形大?12)
plt.tick_params (labelsize=10)
plt.grid(线型=':')
plt。情节(频率(频率的在=0),战俘(频率的在=0),c=橙红色,标签=叭Α?
plt.legend ()
plt.tight_layout ()
plt.show ()
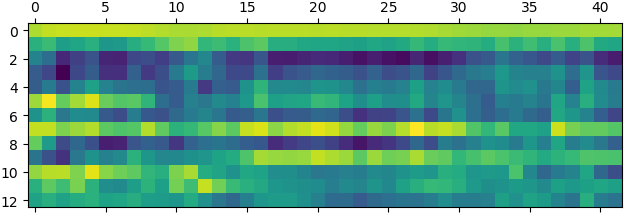
梅尔频率倒谱系数(MFCC)通过与声音内容密切相关的13个特殊频率所对应的能量分布,可以使用梅尔频率倒谱系数矩阵作为语音识别的特征。基于隐马尔科夫模型进行模式识别,找到测试样本最匹配的声音模型,从而识别语音内容。
梅尔频率倒谱系数相关API:
进口scipy.io。wavfile作为wf
进口python_speech_features科幻
sample_rate团体=wf.read(“. ./数据/freq.wav”)
mfcc=科幻。sample_rate mfcc(团体)
案例:画出MFCC矩阵:
python - m pip安装python_speech_features
进口scipy.io。wavfile作为wf
进口python_speech_features科幻
进口matplotlib。pyplot当议员
sample_rate团体=wf.read (
“. ./ml_data/演讲/培训/香蕉/banana01.wav ')
mfcc=科幻。sample_rate mfcc(团体)
mp.matshow (mfcc。T,提出=癵ist_rainbow”)
mp.show ()
隐马尔科夫模型相关API:
进口hmmlearn。嗯,霍奇金淋巴瘤
模型=霍奇金淋巴瘤。GaussianHMM (n_components=4, covariance_type=诊断接头,n_iter=1000)
# n_components:用几个高斯分布函数拟合样本数据
# covariance_type:相关矩阵的辅对角线进行相关性比较
# n_iter:最大迭代上限
model.fit (mfccs) #使用模型匹配测试mfcc矩阵的分得分值=model.score (test_mfccs)
案例:训练训练文件夹下的音频,对测试文件夹下的音频文件做分类
1,读取培训文件夹中的训练音频样本,每个音频对应一个mfcc矩阵,每个mfcc都有一个类别(苹果)。
2,把所有类别为苹果的mfcc合并在一起,形成训练集。
| mfcc |,,,|
苹果| mfcc | |
| mfcc |,,,|
…
由上述训练集样本可以训练一个用于匹配苹果的嗯。
3,训练7个嗯分别对应每个水果类别。保存在列表中。
读 4日取测试文件夹中的测试样本,整理测试样本
苹果 | mfcc | |
| mfcc | lime ,|
& # 8203;
5,针对每一个测试样本:
1,分别使用7个嗯模型,对测试样本计算分数得分。
2,取7个模型中得分最高的模型所属类别作为预测类别。
进口操作系统
进口numpy np
进口scipy.io。wavfile作为wf
进口python_speech_features科幻
进口hmmlearn。嗯,霍奇金淋巴瘤
& # 8203;
# 1。读取培训文件夹中的训练音频样本,每个音频对应一个mfcc矩阵,每个mfcc都有一个类别(苹果)。
def search_file(目录):
#使传过来的目录匹配当前操作系统
#{'苹果':[url网址,网址…),“香蕉”:[…]}
目录=os.path.normpath(目录)
对象={}
# curdir:当前目录
#子目录:当前目录下的所有子目录
#文件:当前目录下的所有文件名
在os.walk curdir、子目录、文件(目录):
文件的文件:
如果file.endswith (“wav”):
标签=curdir.split (os.path.sep) [1]
如果标签没有对象:
对象[标记]=[]
#把路径添加到标签对应的列表中=os.path路径。加入(curdir文件)
对象(标签).append(路径)
返回对象
& # 8203;
#读取训练集数据
train_samples=\
search_file (. ./ml_data/演讲/培训)
& # 8203;
"





