介绍
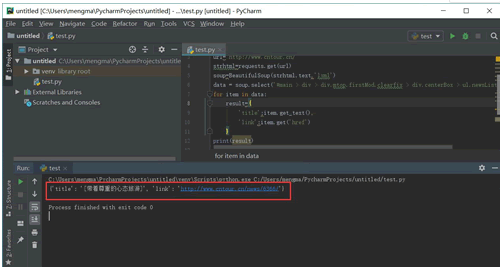
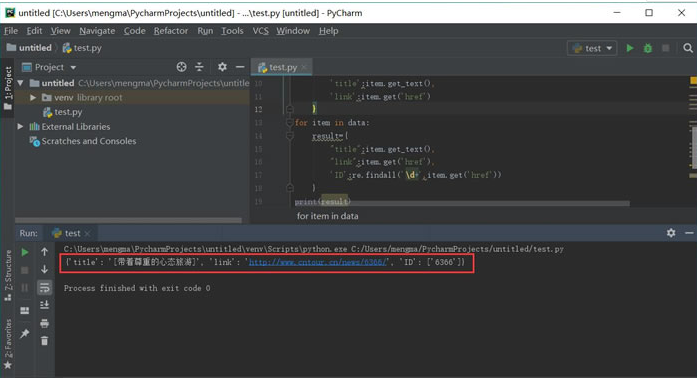
strhtml.text
1
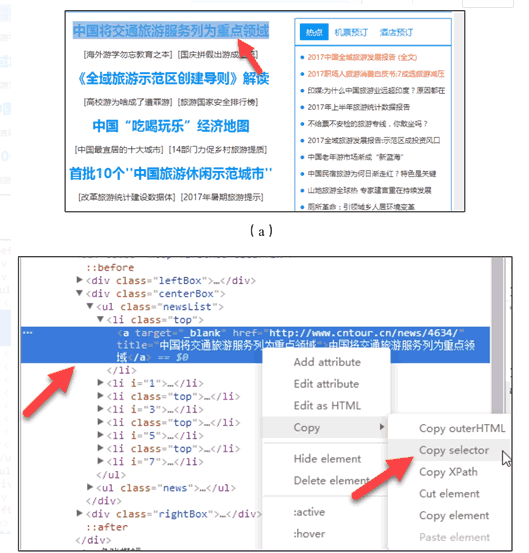
data =, soup.select (& # 39; # main 祝辞,div 祝辞,div.mtop.firstMod.clearfix 祝辞,div.centerBox 祝辞,ul.newsList 祝辞,li 祝辞,一个# 39;)
1
这篇文章给大家分享的是有关使用Python进行网络爬虫的案例分析的内容。小编觉得挺实用的,因此分享给大家做个参考。一起跟随小编过来看看吧。

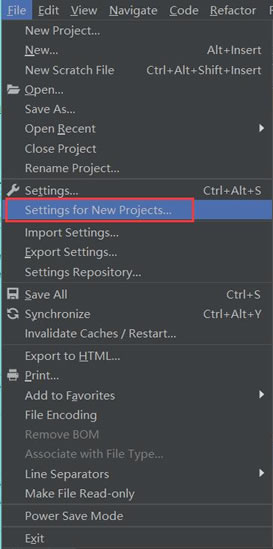
- <李>
<李>
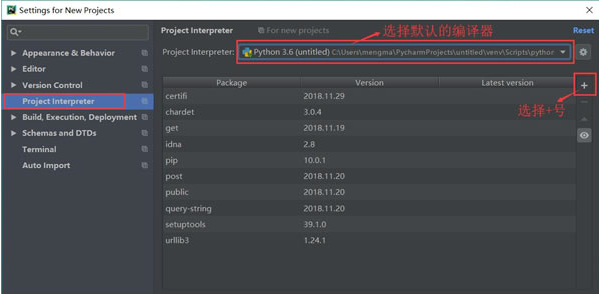
- <李>
<李>
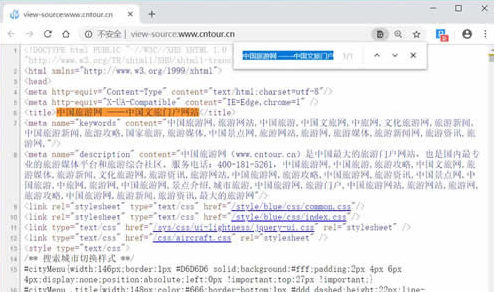
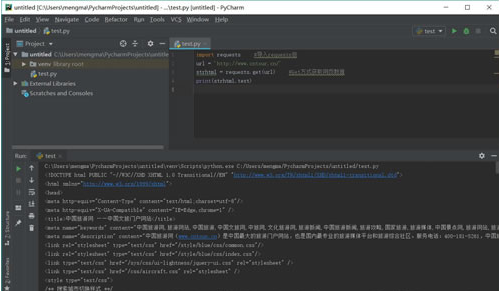
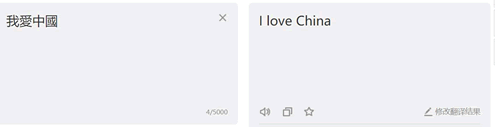
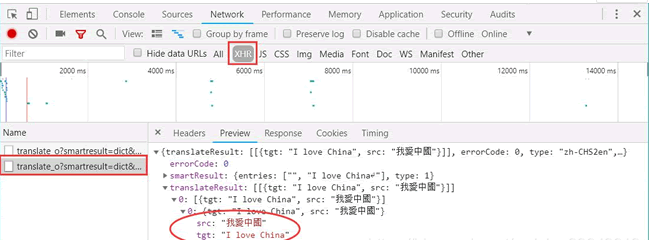
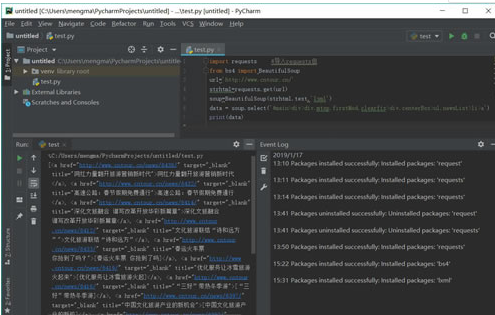
这个时候strhtml是一个URL对象,它代表整个网页,但此时只需要网页中的源码、下面的语句表示网页源码: