在前程无忧上投递简历发现有竞争力分析,免费能看到匹配度评价和综合竞争力分数,可以做投递参考

计算方式
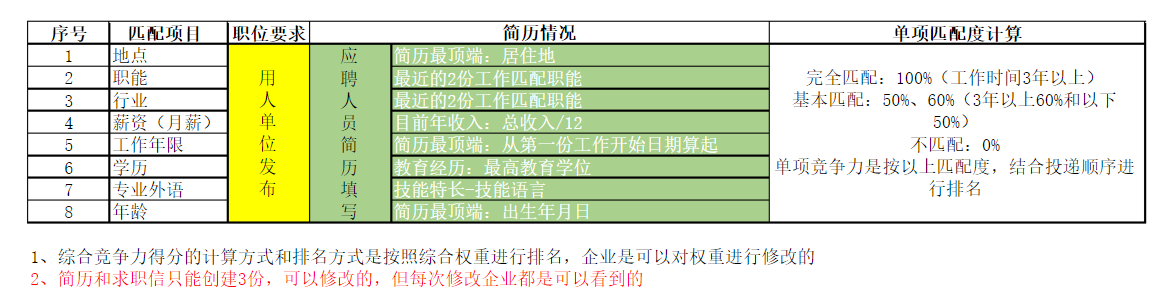
综合竞争力得分应该越高越好,匹配度评语也应该评价越高越好
抓取所有职位关键字搜索结果并获取综合竞争力得分和匹配度评语,最后筛选得分评语自动投递合适的简历
从硒进口webdriver
从selenium.webdriver.chrome。选择导入选项
chrome_options=选项()
# chrome_options.add_argument(“——无头”)
从进口睡眠时间
进口再保险
从lxml进口etree
进口的要求
进口操作系统
进口json
司机=webdriver。铬(chrome_options=chrome_options executable_path=' D: \ python \ chromedriver.exe ')
头={“用户代理”:“Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML,像壁虎)Chrome/73.0.3683.86 Safari 537.36 "}
driver.get (https://search.51job.com/list/020000, 000000、0000、00, 9日,99年,% 2520,2,html 1. # 63; lang=c&药栓=,postchannel=0000, workyear=99,共型=99,degreefrom=99, jobterm=99, companysize=99, providesalary=99, lonlat=0% 2 c0&半径=1,ord_field=0, confirmdate=9, fromType=, dibiaoid=0,地址=,=,行specialarea=00,从=,福利=)
webdriver需要在相应域名写入cookie,所以转到职位搜索页面

def get_cookie ():
driver.get (" https://login.51job.com/login.php& # 63; loginway=1, lang=c& url=")
睡眠(2)
电话=输入(“输入手机号:”)
driver.find_element_by_id (“loginname”) .send_keys(电话)
driver.find_element_by_id (“btn7”) .click ()
睡眠(1)
代码=输入(“输入短信:“)
driver.find_element_by_id (phonecode) .send_keys(代码)
driver.find_element_by_id (“login_btn”) .click ()
睡眠(2)
饼干=driver.get_cookies ()
张开(“饼干。f json”、“w”):
f.write (json.dumps(饼干)
检查饼干文件是否存在,如果不存在执行get_cookie把饼干写入文件,在登陆的时候最好不用无头模式,偶尔有滑动验证码
前程无忧手机短信一天只能发送三条,保存饼干下次登陆用
def get_job ():
driver.get (" https://search.51job.com/list/020000, 000000、0000、00, 9日,99年,% 2520,2,html 1. # 63; lang=c&药栓=,postchannel=0000, workyear=99,共型=99,degreefrom=99, jobterm=99, companysize=99, providesalary=99, lonlat=0% 2 c0&半径=1,ord_field=0, confirmdate=9, fromType=, dibiaoid=0,地址=,=行,specialarea=00,从=,福利=")
睡眠(2)
工作=输入(“输入职位:”)
driver.find_element_by_id (“kwdselectid”) .send_keys(工作)
driver.find_element_by_xpath('//按钮[@class=" p_but "]”) .click ()
url=driver.current_url
页面=driver.page_source
返回的url,页面
在职位搜索获取职位搜索结果,需要返回页面源码和地址


分析页码结构html前的是页码,全部页码数量通过共XX页得到
def get_pages (url,页面):
树=etree.HTML(页面)
href=https://www.yisu.com/zixun/[]
x=tree.xpath('//跨度[@class=皌d”]/text ()”) [0]
total_page=int (re.findall (”(\ d +)”,x) [0])
我的范围(1,total_page + 1):
href.append (re.sub (\ d。html”, f '{我}。html, url))
返回href
获取全部页码

def get_job_code (url):
头={“用户代理”:“Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML,像壁虎)Chrome/73.0.3683.86 Safari 537.36 "}
r=session.get (url,头=标题)
树=etree.HTML (r.text)
div=tree.xpath ('//div [@class=" el "]/p/跨度//@href ')
工作=str (div)
job_id=re.findall (“\/(\ d +) . html”,工作)
返回job_id





