
<>强散列、chunkhash contenthash
哈希一般是结合CDN缓存来使用,通过webpack构建之后,生成对应文件名自动带上对应的MD5值。如果文件内容改变的话,那么对应文件哈希值也会改变,对应的HTML引用的URL地址也会改变,触发CDN服务器从源服务器上拉取对应数据,进而更新本地缓存。但是在实际使用的时候,这几种散列计算还是有一定区别。
我们先建一个测试案例来模拟下:
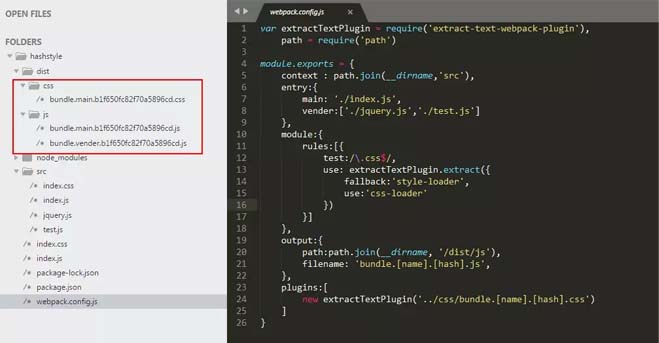
项目结构
我们的项目结构很简单,入口文件index.js,引用了index.css。然后新建了jquery.js和测试。js作为公共库。
接着我们修改webpack.config.js来模拟不同散列计算
<强>哈希
哈希是跟整个项目的构建相关,只要项目里有文件更改,整个项目构建的散列值都会更改,并且全部文件都共用相同的散列值
根据上面的配置,我们执行webpack命令之后,可以得到下面的结果
采用散列计算的执行结果1:

执行结果2:
我们可以看到构建生成的文件散列值都是一样的,所以散列计算是跟整个项目的构建相关,同一次构建过程中生成的哈希都是一样的
<强> chunkhash
采用散列计算的话,每一次构建后生成的哈希值都不一样,即使文件内容压根没有改变。这样子是没办法实现缓存效果,我们需要换另一种哈希值计算方式,即chunkhash。
chunkhash和散列不一样,它根据不同的入口文件(条目)进行依赖文件解析,构建对应的块,生成对应的哈希值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成哈希值,那么只要我们不改动公共库的代码,就可以保证其哈希值不会受影响。
采用chunkhash计算的执行结果1:
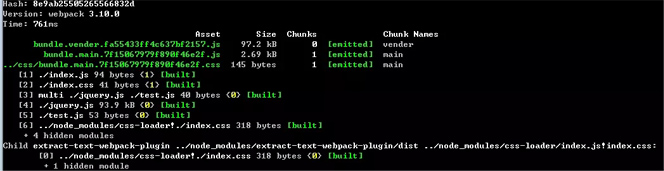
执行结果2:
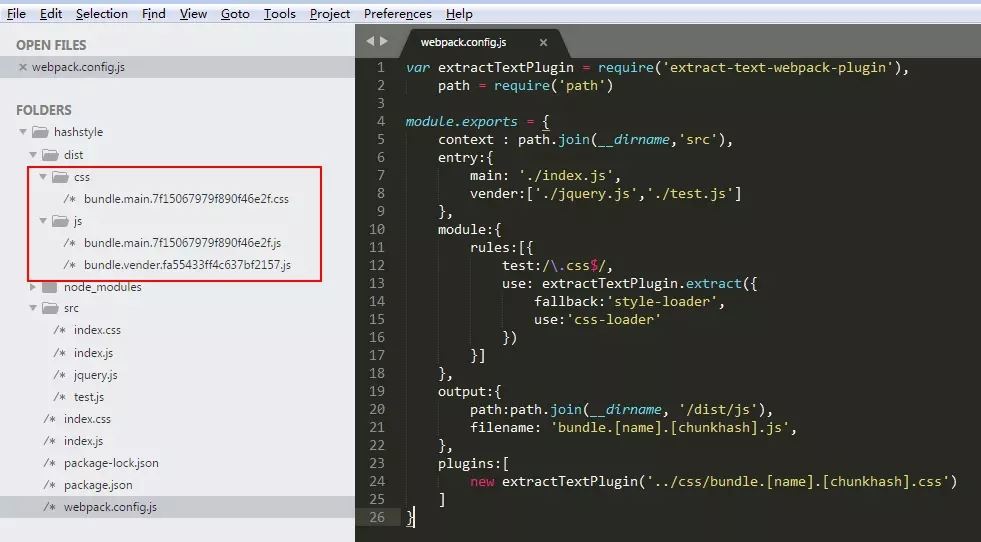
我们可以看的到,由于采用chunkhash,所以项目主入口文件Index.js及其对应的依赖文件Index.css由于被打包在同一个模块,所以共用相同的chunkhash,但是公共库由于是不同的模块,所以有单独的chunkhash。这样子就保证了在线上构建的时候只要文件内容没有更改就不会重复构建
<强> contenthash
在chunkhash的例子,我们可以看到由于index.css被index.js引用了,所以共用相同的chunkhash值。但是这样子有个问题,如果指数。js更改了代码,css文件就算内容没有任何改变,由于是该模块发生了改变,导致css文件会重复构建。




