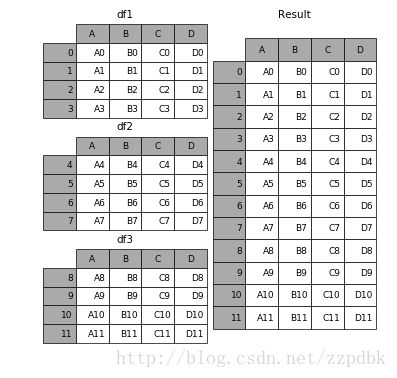
concat()函数的具体用法
参数含义
-
<李> obj:系列,DataFrame或小组对象的序列或映射。如果传递了dict类型,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下)文。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。
<李>轴:{0,1,…},默认为0。沿着连接的轴。
<李>加入:{“内”、“外”},默认为“外”。如何处理其他轴上的索引.outer为联合和内部为交集。
<李> ignore_index:布尔,默认错误。如果为真实,请不要使用并置轴上的索引值。结果轴将被标记为0,…,n - 1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。
<李> join_axes:指数对象列表。用于其他n - 1轴的特定索引,而不是执行内部/外部设置逻辑。
<李>键:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。
<李>级别:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否,则它们将从键推断。
<李>的名字:列表,默认无。结果层次索引中的级别的名称。
<李> verify_integrity:布尔,默认错误。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。
<李>复制:布尔,默认正确。如果为假,请勿不必要地复制数据。<代码>
李
关键参数
结果:
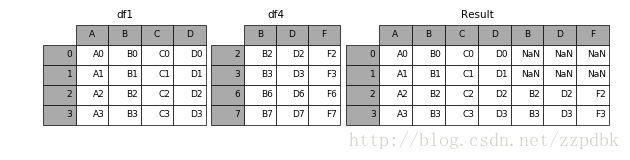
当设置加入=澳谛摹?则说明为取交集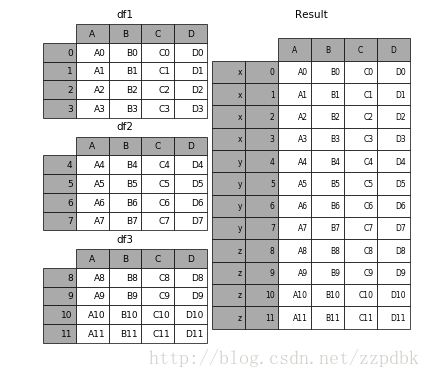 在[8]:df4=pd。DataFrame ({B: [B2, B3, B6, ' B7 '],
…:“D”:“D2、D3, D6, D7”),
…:“F”:“F2、F3, F6, ' F7 ']},
…:指数=[2、3、6、7])
…:
在[9]:结果=pd。concat ([df1, df4],轴=1)
在[8]:df4=pd。DataFrame ({B: [B2, B3, B6, ' B7 '],
…:“D”:“D2、D3, D6, D7”),
…:“F”:“F2、F3, F6, ' F7 ']},
…:指数=[2、3、6、7])
…:
在[9]:结果=pd。concat ([df1, df4],轴=1)
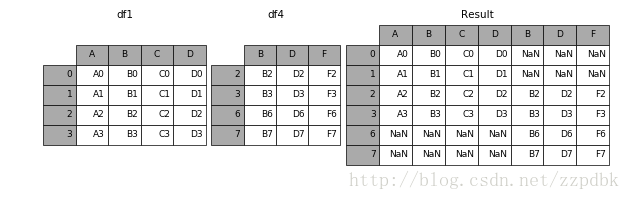
结果:
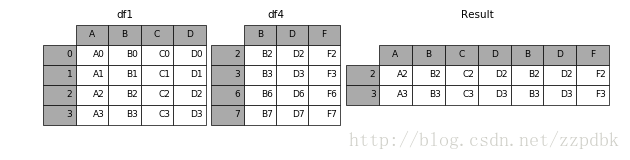 在[11]:结果=pd。concat ([df1, df4],轴=1,join_axes=[df1.index]) #设置索引为df1的索引
在[11]:结果=pd。concat ([df1, df4],轴=1,join_axes=[df1.index]) #设置索引为df1的索引