<>强基于pytorch来讲
MSELoss()多用于回归问题,也可以用于one_hotted编码形式,
CrossEntropyLoss()名字为交叉熵损失函数,不用于one_hotted编码形式
MSELoss()要求batch_x与batch_y的张量都是FloatTensor类型
CrossEntropyLoss()要求batch_x为浮动,batch_y为LongTensor类型
<强> (1)CrossEntropyLoss()举例说明:
比如二分类问题,最后一层输出的为2个值,比如下面的代码:
类CNN (nn。模块):
def __init__(自我、hidden_size1 output_size dropout_p):
超级(CNN,自我)。__init__ ()
自我。hidden_size1=hidden_size1
自我。output_size=output_size
自我。dropout_p=dropout_p
自我。conv1=nn。Conv1d(1、8、3、填充=1)
自我。fc1=nn。线性(8 * 500,自我。hidden_size1)
自我。=nn。线性(self.hidden_size1自我。output_size)
def向前(自我,encoder_outputs):
cnn_out=F。max_pool1d (F。relu (self.conv1 (encoder_outputs)), 2)
cnn_out=F。辍学(cnn_out self.dropout_p) #加一个辍学
cnn_out=cnn_out。视图(1,8 * 500)
output_1=火炬。双曲正切(自我。fc1 (cnn_out))
输出=自我。(ouput_1)
返回输出
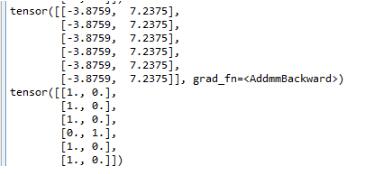
最后的输出结果为:

上面一个张量为输出结果,下面为目标,没有使用one_hotted编码。
<>强训练过程如下:
cnn_optimizer=torch.optim.SGD (cnn.parameters ()、learning_rate动量=0.9,\
weight_decay=1 e-5)
标准=nn.CrossEntropyLoss ()
def火车(input_variable target_variable, cnn, cnn_optimizer标准):
cnn_output=cnn (input_variable)
打印(cnn_output)
打印(target_variable)
损失=标准(cnn_output target_variable)
cnn_optimizer。zero_grad ()
的损失。向后()
cnn_optimizer。步骤()
#打印(失:,loss.item ())
返回loss.item() #返回损失
之前
说明CrossEntropyLoss()是输出两位为one_hotted编码形式,但目标不是one_hotted编码形式。
<强> (2)MSELoss()举例说明:
网络结构不变,但是标签是one_hotted编码形式。下面的图仅做说明,网络结构不太对,出来的预测也不太对。
如果不目标是one_hotted编码形式会报,错报的错误如下。

目前自己理解的两者的区别,就是这样的,至于多分类问题是不是也是样的有待考察。
以上这篇基于MSELoss()与CrossEntropyLoss()的区别详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。





