本文主要是用PyTorch来实现一个简单的回归任务。
编辑器:世爵
进口火炬
进口torch.nn。功能是f#主要实现激活函数
进口matplotlib。pyplot作为plt #绘图的工具
从火炬。autograd导入变量
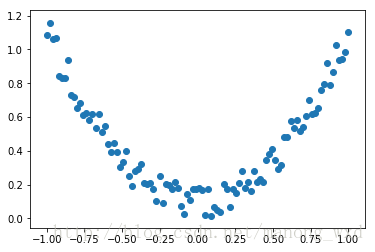
#生成伪数据
x=torch.unsqueeze(火炬。linspace(1, - 1, 100),暗=1)
y=x.pow (2) + 0.2 * torch.rand (x.size ())
#变为变量
x, y=变量(x)变量(y)
之前
其中<代码> torch.linspace> torch.unsqueeze> torch.rand 返回的是(0,1)之间的均匀分布。
在上述代码后面加下面的代码,然后运行可得伪数据的图形化表示:
#绘制数据图像
y.data.numpy plt.scatter (x.data.numpy () ()
plt.show ()
类网(torch.nn.Module):
def __init__(自我、n_feature n_hidden n_output):
超级(净,自我). __init__ ()
自我。隐藏=torch.nn。线性(n_feature n_hidden) #隐藏层
自我。预测=torch.nn。线性(n_hidden n_output) #输出层
def向前(自我,x):
x=F.relu (self.hidden (x) #激活函数为隐层
x=self.predict (x) #线性输出
返回x
网=净(n_feature=1, n_hidden=10, n_output=1) #定义网络
打印(净)#网的体系结构
之前
一般神经网络的类都继承自<代码> torch.nn.Module ,<代码>向前__init__()和()两个函数是自定义类的主要函数。在<代码> __init__() 中都要添加一句<代码>超级(净,自我). __init__() 这是固定的标准写法,用于继承父类的初始化函数。<代码> __init__() 中只是对神经网络的模块进行了声明,真正的搭建是在<代码>前进()中实现。自定义类中的成员都通过自我指针来进行访问,所以参数列表中都包含了自我。
如果想查看网络结构,可以用<代码>打印()函数直接打印网络。本文的网络结构输出如下:
净(
(隐藏):线性(1→10)
(预测):线性(10→1)
)
之前
#训练100次
t的范围(100):
预测=净(x) #输入x和基于预测的>
plt.ion() #策划
t的范围(100):
…
如果t % 5==0:
#情节和展示学习过程
plt.cla ()
y.data.numpy plt.scatter (x.data.numpy () ()
prediction.data.numpy plt.plot (x.data.numpy () ()、r -, lw=5)
plt.text(0.5, 0, '损失=%。4 f ' %的损失。数据[0],fontdict={“大小”:20,“颜色”:“红色”})
plt.pause (0.1)
plt.ioff ()
plt.show ()
之前
 PyTorch学习笔记之回归实战
PyTorch学习笔记之回归实战





