
这两天遇到一个服务假死的问题,具体现象就是服务不再接收任何请求,客户端会抛出破管。
执行,发现CPU和内存占用都不高,但是通过命令
发现有大量的CLOSE_WAIT端口占用,继续调用该服务的api,等待超时之后发现CLOSE_WAIT的数量也没有上升,也就是说服务几乎完全僵死。
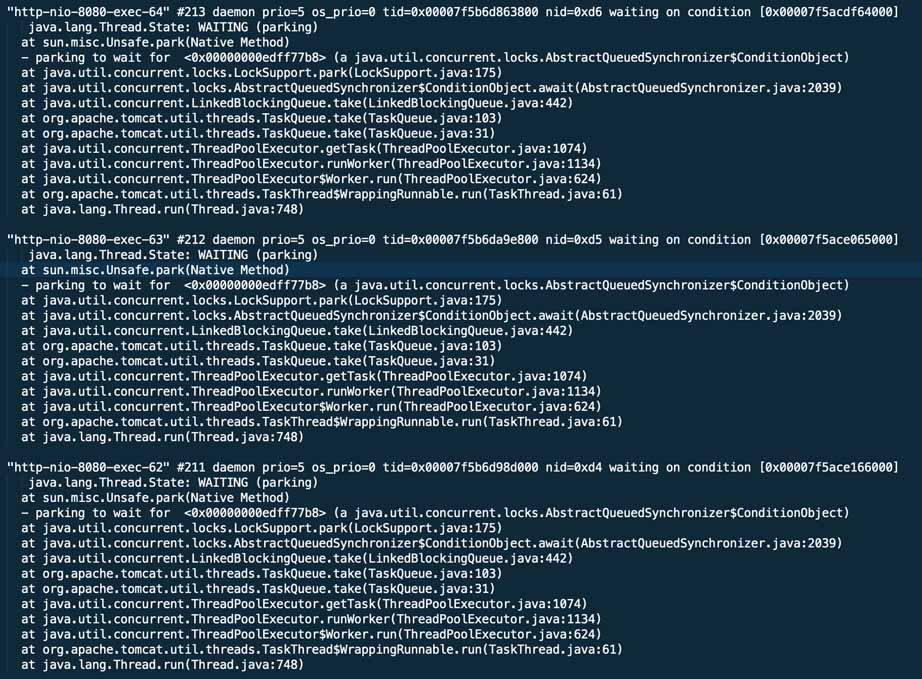
怀疑可能是线程有死锁,决定先转储一下线程情况,执行
发现tomcat线程基本也正常,都是停车状态。
这就比较奇怪了,继续想是不是GC导致了STW,使用jstat查看垃圾回收情况
一看吓一跳,第五代计算机的次数居然超过了YGC,时长有475年代。一定是有什么原因触发了第五代计算机,好在我们打开了GC日志。
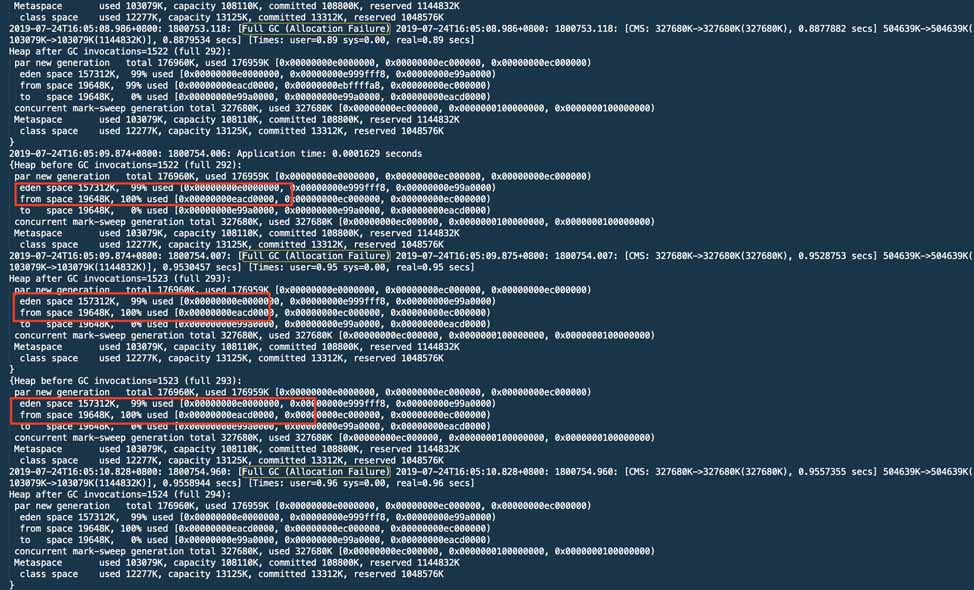
发现一段时间内频繁发生分配失败引起的完整GC。而且伊甸园区的使用占比也很大,考虑有频繁新建对象逃逸到老年代造成问题。询问了一下业务的开发,确认有一个外部对接API没有分页,查询后可能会产生大量对象。
由于外部API暂时无法联系对方修改,所以为了先解决问题,对原有的MaxNewSize进扩容,从192 mb扩容到一倍。经过几天的观察,发现gc基本趋于正常
扩容之前对堆进行了转储
通过垫分析内存泄露,居然疑似是jdbc中的一个类,但其实整体占用堆容量并不多。

分析了线程数量,大约是240多条,与正常时也并没有很大的出入。而且大量的是在睡眠的定时线程。
本次排查其实并未找到真正的原因,间接表象是第五代计算机频繁导致服务假死。而且acturator端口是正常工作的,导致健康检查进程误认为服务正常,没有触发告警。如果你也遇到类似的情况欢迎一起讨论。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。




