Python 3利用Dlib 19.7实现摄像头人脸检测特征点标定
<强> 0。引言
利用python开发,借助Dlib库捕获摄像头中的人的脸,进行实时特征点标定;
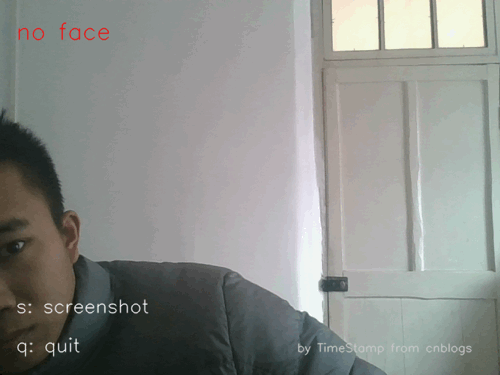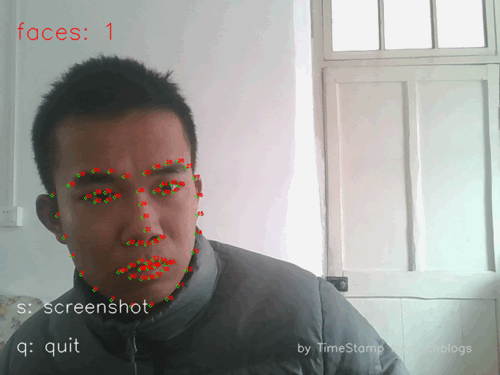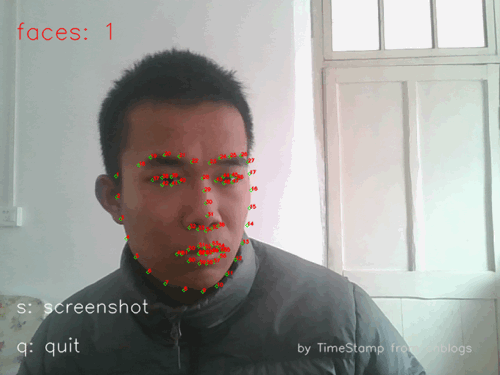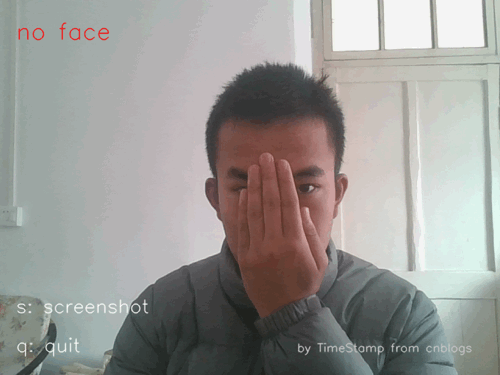
图1工程效果示例(gif)
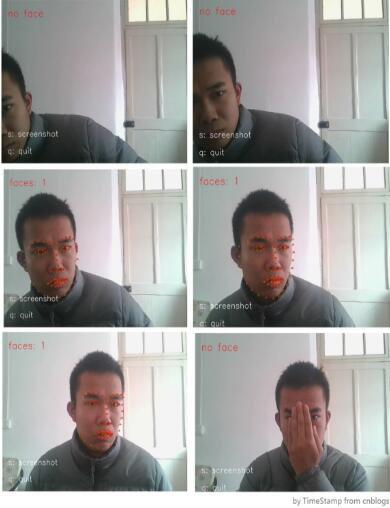
图2工程效果示例(静态图片)
(实现比较简单,代码量也比较少,适合入门或者兴趣学习。)
<强> 1。开发环境
python: 3.6.3
dlib: 19.7
OpenCv, numpy
进口dlib #人脸识别的库dlib
进口numpy np #数据处理的库numpy
进口cv2 #图像处理的库OpenCv
<强> 2。源码介绍
其实实现很简单,主要分为两个部分:摄像头调用+人脸特征点标定
2.1摄像头调用
介绍下opencv中摄像头的调用方法;
利用帽=cv2.VideoCapture(0)创建一个对象,
(具体可以参考官方文档)
# 2018-2-26
#通过时间戳
# cnblogs: http://www.cnblogs.com/AdaminXie
”“”
cv2.VideoCapture(),创建cv2摄像头对象/打开默认的相机
Python: cv2.VideoCapture ()→& lt; VideoCapture object>
Python: cv2.VideoCapture(文件名)→& lt; VideoCapture object>
文件名,打开视频文件的名称(如:video.avi)或图像序列(如。img_ % 02 d.jpg,阅读样本像img_00.jpg img_01.jpg img_02.jpg,……)
Python: cv2.VideoCapture(设备)→& lt; VideoCapture object>
设备- id的打开视频捕获设备(即摄像机指数)。如果有一个摄像头连接,只是通过0。
”“”
帽=cv2.VideoCapture (0)
”“”
cv2.VideoCapture。集(propId价值),设置视频参数;
propId:
CV_CAP_PROP_POS_MSEC视频文件的当前位置,以毫秒为单位。
CV_CAP_PROP_POS_FRAMES基于索引的帧解码/捕获。
CV_CAP_PROP_POS_AVI_RATIO视频文件的相对位置:0 -电影,开始1 -电影结束。
CV_CAP_PROP_FRAME_WIDTH视频帧的宽度。
CV_CAP_PROP_FRAME_HEIGHT视频帧流的高度。
CV_CAP_PROP_FPS帧速率。
CV_CAP_PROP_FOURCC角色代码的编解码器。
在视频文件CV_CAP_PROP_FRAME_COUNT的帧数。
垫的CV_CAP_PROP_FORMAT格式检索()返回的对象。
CV_CAP_PROP_MODE后端特定值指示当前捕获模式。
CV_CAP_PROP_BRIGHTNESS亮度图像的相机(只)。
CV_CAP_PROP_CONTRAST对比图像的相机(只)。
CV_CAP_PROP_SATURATION饱和度图像的相机(只)。
CV_CAP_PROP_HUE色调图像的相机(只)。
CV_CAP_PROP_GAIN获得图像的相机(只)。
CV_CAP_PROP_EXPOSURE曝光相机(只)。
CV_CAP_PROP_CONVERT_RGB布尔标志指示是否应该转换为RGB图像。
CV_CAP_PROP_WHITE_BALANCE_U whitebalance的U值设置(注意:>
#通过时间戳
# cnblogs: http://www.cnblogs.com/AdaminXie
# github: https://github.com/coneypo/Dlib_face_detection_from_camera
进口dlib #人脸识别的库dlib
进口numpy np #数据处理的库numpy
进口cv2 #图像处理的库OpenCv
# dlib预测器
探测器=dlib.get_frontal_face_detector ()
预测=dlib.shape_predictor (“shape_predictor_68_face_landmarks.dat”)
#创建cv2摄像头对象
帽=cv2.VideoCapture (0)
# cap.set (propId值)
#设置视频参数,propId设置的视频参数,值设置的参数的值
cap.set (480)
#截图screenshoot的计数器
问=0
# cap.isOpened()返回真/假检查初始化是否成功
而(cap.isOpened ()):
# cap.read ()
#返回两个值:
#一个布尔值true/false,用来判断读取视频是否成功是/否到视频末尾
#图像对象,图像的三维矩阵
国旗,im_rd=cap.read ()
#每帧数据延时1 ms,延时为0读取的是静态帧
k=cv2.waitKey (1)
#取灰度
img_gray=cv2。cvtColor (im_rd cv2.COLOR_RGB2GRAY)
#人脸数矩形
矩形=检测器(img_gray, 0)
#打印(len(矩形)
#待会要写的字体
字体=cv2.FONT_HERSHEY_SIMPLEX
#标68个点
如果(len(矩形)!=0):
#检测到人的脸
因为我在范围(len(矩形)):
地标=np.matrix ([[p。x, p。y)在预测p (im_rd,矩形[我]).parts ()))
idx,枚举点(标志):
# 68点的坐标
pos=(点(0,0),点[0,1])
#利用cv2.circle给每个特征点画一个圈,共68个
cv2。圆(im_rd pos 2颜色=(0 255 0))
#利用cv2.putText输出1 - 68
cv2。putText (im_rd str (idx + 1), pos,字体,0.2 (0,0,255),1,cv2.LINE_AA)
cv2。putText (im_rd,“脸:“+ str (len(矩形)),(20、50),字体,1,(0,0,255),1,cv2.LINE_AA)
其他:
#没有检测到人的脸
cv2。putText (im_rd,“没有脸”,(20、50),字体,1,(0,0,255),1,cv2.LINE_AA)
#添加说明
im_rd=cv2。putText (im_rd,“年代:截图”,(400),字体,0.8,(255、255、255),1,cv2.LINE_AA)
im_rd=cv2。putText (im_rd,“问:辞职”,(450),字体,0.8,(255、255、255),1,cv2.LINE_AA)
#按下s键保存
如果(k==奥德(“s”):
问+=1
cv2.imwrite (“screenshoot”+ str(问)+ " . jpg ", im_rd)
#按下q键退出
如果(k==奥德(q)):
打破
#窗口显示
cv2。imshow(“相机”,im_rd)
#释放摄像头
cap.release ()
#删除建立的窗口
cv2.destroyAllWindows ()