在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解。确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料。今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下TensorFlow的数据读取机制,文章的最后还会给出实战代码以供参考。
<强> TensorFlow读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
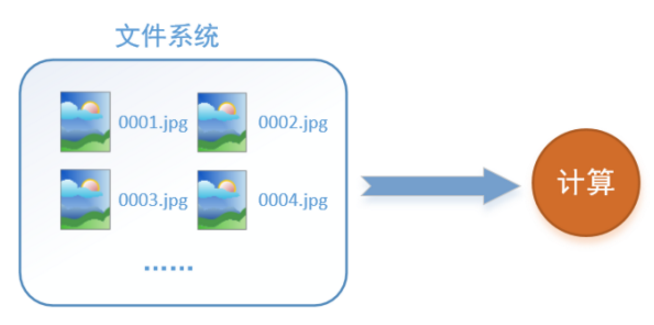
假设我们的硬盘中有一个图片数据集0001. jpg, 0002. jpg, 0003. jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用0.1时,计算用时0.9秒,那么就意味着每过1 s, GPU都会有0.1秒无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队,列如下图所示:
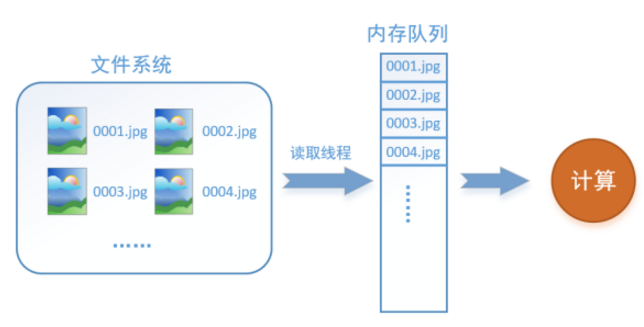
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题。
而在TensorFlow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:时代。对于一个数据集来讲,运行一个时代就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg, B.jpg, C.jpg,那么跑一个时代就是指对A, B, C三张图片都计算了一遍。两个时代就是指先对A, B, C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
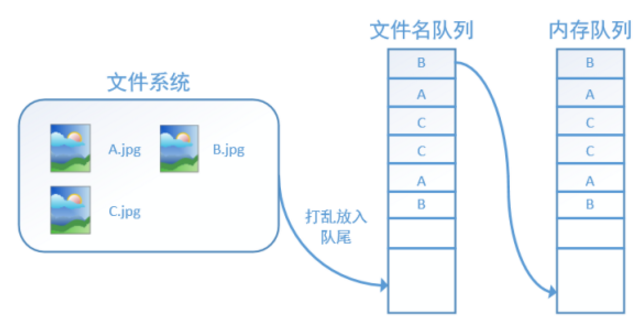
TensorFlow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理时代。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个时代,那么我们就在文件名队列中把A, B, C各放入一次,并在之后标注队列结束。
程序运行后,内存队列首先读入一个(此时一个从文件名队列中出队):
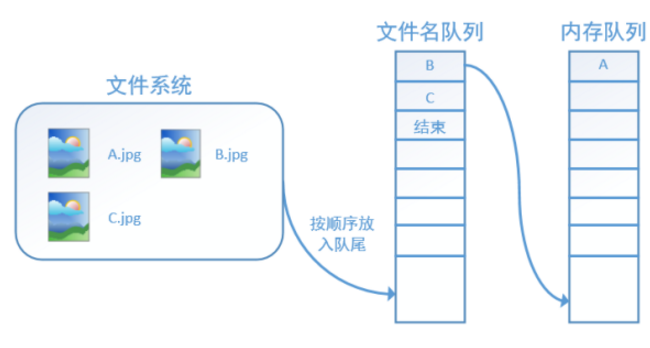
再依次读入B和C:
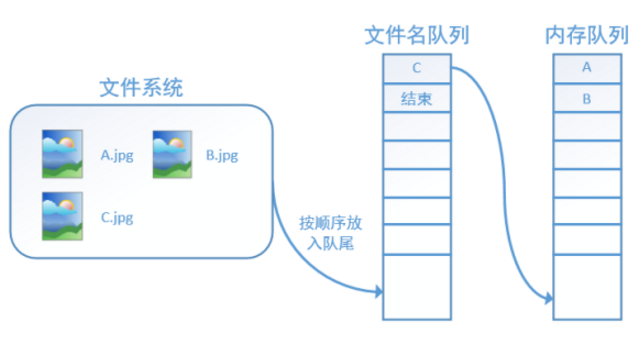
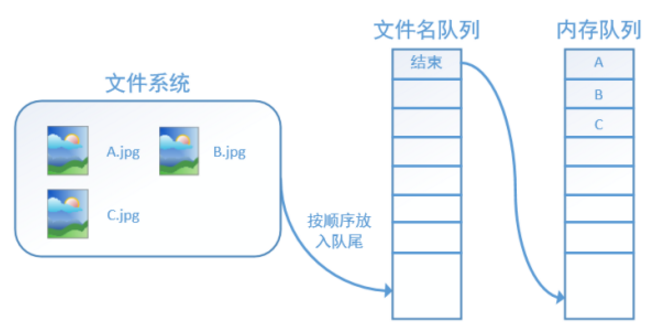
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是TensorFlow中读取数据的基本机制。如果我们要跑2个时代而不是一个时代,那只要在文件名队列中将A, B, C依次放入两次再标记结束就可以了。
<强> TensorFlow读取数据机制的对应函数
如何在TensorFlow中创建上述的两个队列呢?
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名名单,系统会自动将它转为一个文件名队列。
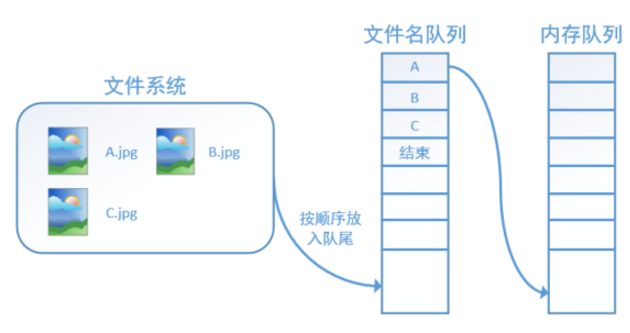
此外tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的时代数。另外一个就是洗牌,洗牌是指在一个时期内文件的顺序是否被打乱。若设置洗牌=False,如下图,每个纪元内,数据还是按照A, B, C的顺序进入文件名队列,这个顺序不会改变:

如果设置洗牌=True,那么在一个时期内,数据的前后顺序就会被打乱,如下图所示: