去自从出生就身带“高并发”的标签,其并发编程就是由groutine实现的,因其消耗资源低,性能高效、开发成本低的特性而被广泛应用到各种场景,例如服务端开发中使用的HTTP服务,在golang net/http包中,每一个被监听到的tcp链接都是由一个groutine去完成处理其上下文的,由此使得其拥有极其优秀的并发量吞吐量
为{//监听tcp
rw, e:=l.Accept ()
如果e !=nil {
……
}
tempDelay=0
c:=srv.newConn (rw)
c.setState (c。rwc, StateNew)//之前可以返回//启动协程处理上下文
去c.serve (ctx)
}
虽然创建一个groutine占用的内存极小(大约2 kb左右,线程通常2 m左右),但是在实际生产环境无限制的开启协程显然是不科学的,比如上图的逻辑,如果来几千万个请求就会开启几千万个groutine,当没有更多内存可用时,去的调度器就会阻塞groutine最终导致内存溢出乃至严重的崩溃,所以本文将通过实现一个简单的协程池,以及剖析几个开源的协程池源码来探讨一下对groutine的并发控制以及多路复用的设计和实现。
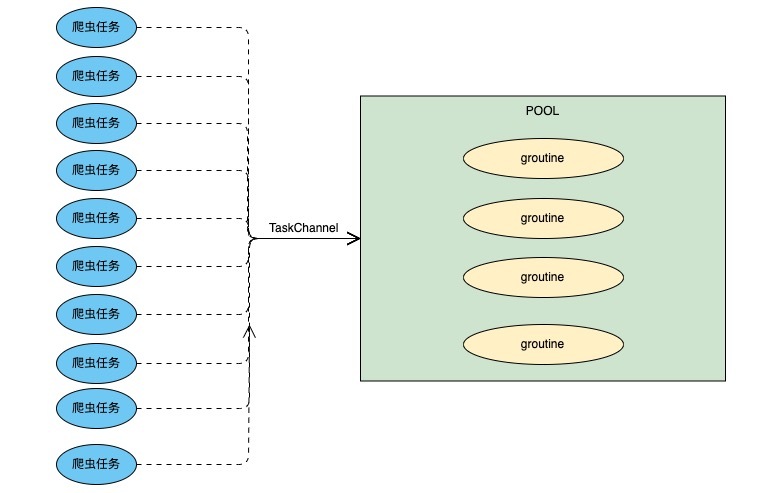
过年前做过一波小需求,是将主播管理系统中信息不完整的主播找出来然后再到其相对应的直播平台爬取完整信息并补全,当时考虑到每一个主播的数据都要访问一次直播平台所以就用应对每一个主播开启一个groutine去抓取数据,虽然这个业务量还远远远远达不到能造成groutine性能瓶颈的地步,但是心里总是不舒服,于是放假回来后将其优化成从协程池中控制groutine数量再开启爬虫进行数据抓取。思路其实非常简单,用一个通道当做任务队列,初始化groutine池时确定好并发量,然后以设置好的并发量开启groutine同时读取通道中的任务并执行,模型如下图
实现
SimplePool struct类型{
wg sync.WaitGroup
工作陈func()//任务队列
}
func NewSimplePoll(工人int) * SimplePool {
p:=, SimplePool {
wg: sync.WaitGroup {},
工作:使(陈func ()),
}
p.wg.Add(工人)//根据指定的并发量去读取管道并执行
我:=0;我& lt;工人;我+ + {
去func () {
推迟func () {//捕获异常防止waitGroup阻塞
如果犯错:=()恢复;犯错!=nil {
fmt.Println (err)
p.wg.Done ()
}
} ()//从workChannel中取出任务执行
fn:=p。{工作
fn ()
}
p.wg.Done ()
} ()
}
返回p
}//添加任务
func (p * SimplePool)添加(fn func ()) {
p。工作& lt; - fn
}//执行
func (p * SimplePool) Run () {
关上(p.work)
p.wg.Wait ()
}
之前
测试
测试设定为在并发数量为20的协程池中并发抓取一百个人的信息,因为代码包含较多业务逻辑所以睡眠1秒模拟爬虫过程,理论上执行时间为5秒
func TestSimplePool (t * testing.T) {
p:=NewSimplePoll (20)
我:=0;我& lt;100;我+ + {
p.Add (parseTask(我))
}
p.Run ()
}
func parseTask (int) func () {
返回func () {//模拟抓取数据的过程
time . sleep(时间。第二个* 1)
fmt。Println(“完成解析”,我)
}
}
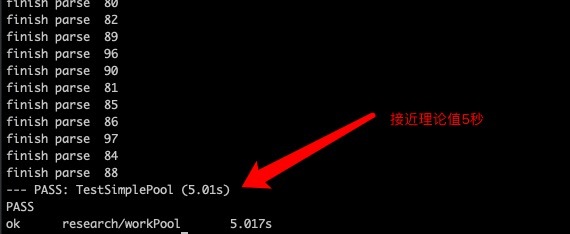
这样一来最简单的一个groutine池就完成了
上面的groutine池虽然简单,但是对于每一个并发任务的状态,池的状态缺少控制,所以又去看了一下go-playground/池的源码实现,先从每一个需要执行的任务入手,该库中对并发单元做了如下的结构体,可以看到除工作单元的值,错误,执行函数等,还用了三个分别表示,取消,取消中,写的三个并发安全的原子操作值来标识其运行状态。
//需要加入池中执行的任务
接口类型WorkFunc func(吴WorkUnit)({},错误)//工作单元
workUnit struct类型{
价值界面{}//任务结果
犯错的错误//任务的报的错
陈做结构{}//通知任务完成
fn WorkFunc
取消了原子。价值//任务是否被取消
取消原子。//值是否正在取消任务
写作原子。价值//任务是否正在执行
}
之前
接下来看池的结构





